

Chercher
- Détails
- Catégorie : Base de Données
- Affichages : 30704
1) Introduction
2) Caractéristiques
Architecture trischématique ou architecture ANSI/SPARC
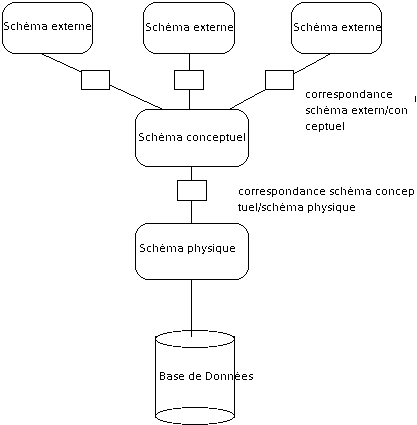 |
|||
| figure 1.0 |
Le processus de transformation des requêtes et des résultats qui sortent d'un niveau à un autre s'appelle correspondance ou mapping.
2.5.1) Le niveau externe
Le niveau externe (appelé aussi niveau vue), comprend une quantité de vues utilisateurs ; chaque utilisateur décrit une partie de la base qui convient à ses besoins. Chaque groupe d'utilisateurs s'intéresse uniquement à son propre schéma externe et les SGBD doivent transformer toute demande d'utilisateur de haut niveau en requêtes de schéma conceptuel puis en requêtes de schéma interne appliquées aux données stockées.
2.5.2) Le niveau conceptuel
Dans le niveau conceptuel on décrit la structure générale de la base de données du point de vu de la communauté des utilisateurs ; c'est un schéma conceptuel qui masque les détails des structures de stockage physique des données et qui ne se soucie pas de l’implémentation physique des données ni de la façon dont chaque groupe d'utilisateurs voudra se servir de la base de données ; ce niveau se concentre sur la description des entités, du type des données, des relations existant entre les entités et des opérartions des utilisateurs.
Dans le cas des SGBD relationnels, il s’agit d’une vision tabulaire où la sémantique de l’information est exprimée en utilisant les concepts de relation, attributs et de contraintes d’intégrité. Le niveau conceptuel est défini au travers du schéma conceptuel.
2.5.3) Le niveau interne
Le niveau interne est un schéma qui décrit la structure de stockage physique de la base de données. IL s’appuie sur un système de gestion de fichiers pour définir la politique de stockage ainsi que le placement des données. Le niveau physique est donc responsable du choix de l’organisation physique des fichiers ainsi que de l’utilisation de méthodes d’accès en fonction de la requête.
3) Indépendances des données


- Détails
- Catégorie : Base de Données
- Affichages : 7523
III) SGBD
2) Modèle relationnel
3. Hypothèses sur les SGBD
4) Opérations sur les bases de données relationnelles
5) Langage SQL
- Détails
- Catégorie : Base de Données
- Affichages : 5094
Le modèle relationnel des données
Généralités
Le modèle relationnel de données a été défini en 1970 par Codd et les premiers systèmes commerciaux sont apparus au début des années 80. Le modèle relationnel est simple (3 concepts), facile à appréhender, même pour un non spécialiste et repose sur de solides bases théoriques qui permettent notamment de définir de façon formelle les langages de manipulation associés.
Le modèle relationnel représente l'information dans une collection de relations. Intuitivement, on peut voir une relation comme une table à double entrée, voire même comme un fichier. Chaque ligne de la table (appelée nuplet ou tuple) peut être vue comme un fait décrivant une entité du monde. Une colonne de la table est appelée un attribut.
Le modèle relationnel, contrairement à ceux présentés dans le chapitre précédent, ne manipule pas des structures de données figées, mais des valeurs : aucun chemin d'accès n'est préalablement défini (on ne parlera désormais plus de déplacements ou de langages navigationnels), toute manipulation des données est désormais possible. L'important bagage théorique, et la vision tabulaire des informations, qui est agréable à l'utilisateur, assurent le succès du modèle relationnel.
Domaines
Un domaine est un ensemble de valeurs (distinctes). Cette définition correspond à l'ensemble des valeurs que peut prendre une certaine manifestation du monde réel. Elle s'apparente souvent à un type (entier, réel), mais peut également être hétéroclite (date). Dans l'exemple précédent, un domaine est l'ensemble des valeurs d'une colonne d'un tableau : {'Mauvaise', 'Excellente', 'Bonne'} est un domaine.
Produit cartésien
Le produit cartésien d'un ensemble de domaines D1, D2,..., Dn, noté D1xD2x…xDn, est l'ensemble de n-uplets (ou tuples) <v1, v2,…, vn> tels que vi Î Di.
Relation : définition
une relation est un sous-ensemble du produit cartésien d'une liste de domaines.
(en construction ).....
Caractéristiques des relations
(en construction)
L'algèbre relationnelle
Généralités
L'algèbre relationnelle est le langage interne d'un SGBD relationnel. Elle se compose d'opérateurs de manipulation des relations. Ces opérateurs sont regroupés en deux familles, chacune de ces contenant quatre opérateurs.
les opérateurs ensemblistes (Union, intreection, différence et produit cartésien) et les opérateurs relationnels (la restriction,la projection, la jointure et la division).
- Détails
- Catégorie : Base de Données
- Affichages : 6047
II) Modélisation
2) Modèle Entité-Relation (modèle E-R)
3) Forme normale
4) Méthodologie de conception
4.2 Processus de conception
- Détails
- Catégorie : Base de Données
- Affichages : 5553
1) Introduction
2) Caractéristiques
Architecture trischématique ou architecture ANSI/SPARC
|
|||
| figure 1.0 |
Le processus de transformation des requêtes et des résultats qui sortent d'un niveau à un autre s'appelle correspondance ou mapping.
2.5.1) Le niveau externe
Le niveau externe (appelé aussi niveau vue), comprend une quantité de vues utilisateurs ; chaque utilisateur décrit une partie de la base qui convient à ses besoins. Chaque groupe d'utilisateurs s'intéresse uniquement à son propre schéma externe et les SGBD doivent transformer toute demande d'utilisateur de haut niveau en requêtes de schéma conceptuel puis en requêtes de schéma interne appliquées aux données stockées.
2.5.2) Le niveau conceptuel
Dans le niveau conceptuel on décrit la structure générale de la base de données du point de vu de la communauté des utilisateurs ; c'est un schéma conceptuel qui masque les détails des structures de stockage physique des données et qui ne se soucie pas de l’implémentation physique des données ni de la façon dont chaque groupe d'utilisateurs voudra se servir de la base de données ; ce niveau se concentre sur la description des entités, du type des données, des relations existant entre les entités et des opérartions des utilisateurs.
Dans le cas des SGBD relationnels, il s’agit d’une vision tabulaire où la sémantique de l’information est exprimée en utilisant les concepts de relation, attributs et de contraintes d’intégrité. Le niveau conceptuel est défini au travers du schéma conceptuel.
2.5.3) Le niveau interne
Le niveau interne est un schéma qui décrit la structure de stockage physique de la base de données. IL s’appuie sur un système de gestion de fichiers pour définir la politique de stockage ainsi que le placement des données. Le niveau physique est donc responsable du choix de l’organisation physique des fichiers ainsi que de l’utilisation de méthodes d’accès en fonction de la requête.
3) Indépendances des données

