

Chercher
- Détails
- Catégorie : Oracle
- Affichages : 7177
1 Introduction à PL/SQL
PL/SQL est un acronyme de "Procedural Language/Structured Query Language". PL/SQL est une extension de SQL proposée par Oracle ; c'est donc un langage spécifique de la base de donnnées Oracle . C'est un langage de quatrième génération i.e un langage 4GL(fourth-generation programming language) permettant de faire des traitements avec
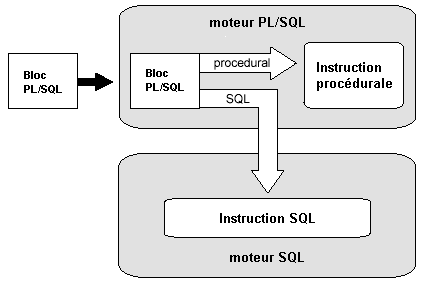 |
| figure 1.0 |
Un programme PL/SQL est structuré en blocs et chaque bloc est constitué d'un ensemble d'instructions :
Un bloc PL/SQL peut être "externe" et dans ce cas on parle de bloc anonyme, ou alors stocké dans la base de données sous forme de procédure, de fonction ou de trigger. Un bloc PL/SQL est intégralement envoyé au moteur PL/SQL, qui traite chaque instruction PL/SQL et sous-traite les instructions purement SQL au moteur SQL, afin de réduire le trafic réseau (pour les application ne résident pas sur la même machine que la base de données ).
Chaque bloc PL/SQL est constitué d'au plus 3 sections :
1 Une section facultative de déclaration et initialisation de types, variables et constantes
2 Une section obligatoire contenant les instructions d'exécution
3 Une section facultative de gestion des erreurs
[DECLARE ... déclarations et initialisation] BEGIN ... instructions exécutables [EXCEPTION ... interception des erreurs] END;
BEGIN Null ; END ;
6 Types de données scalaires
PL/SQL posssède un certain nombre de types scalaires ( on appelle type scalaires en informatique les types non composé comme les structures ou les Unions en C/C++); Ces types de données peuvent être soient :
1 Booléen 2 Date/heure 3 caractère 4 Nombre
6.1 Booléen
6.2 Date/Heure
Date : premier jour du mois courant Heure : minuit
6.3 caractère
CHAR, VARCHAR2, LONG, RAW et LONG RAW.
Ce paramétre de longueur, max_len, doit être un entier littéral et non une constante ou une variable. La table ci-dessous montre les longueurs maximales et les largeurs des colonnes de la base pour les types de données caractère.
| Type de données | CHAR | VARCHAR2 | LONG | RAW | LONG RAW |
| Longueur maximale | 32767 | 32767 | 32760 | 32767 | 32760 |
| Largeur maximale de colonne | 255 | 2000 | 2147483647 | 255 | 2147483647 |
6.4 Nombre
BINARY_INTEGER et NUMBER.
BINARY_INTEGER :
stocke des entiers signés sur l'étendue de ..231 à 231 .. 1. L'utilisation la plus courante de ce type de donnée est celle d'un index pour des tables PL/SQL. Le stockage de nombres de taille fixe ou flottants de n'importe quelle taille est possible avec le type de donnée NUMBER. Pour des nombres flottants, la précision et l'échelle peuvent être spécifiés avec le format suivant :
NUMBER(10,2)
Une variable déclarée de cette manière a un maximum de 10 chiffres et l'arrondi se fait à deux décimales. La précision par défaut est le plus grand entier supporté par le systéme et 0 est l'échelle par défaut. L'intervalle de précision va de 1 à 38 alors que l'échelle va de ..84 à 127.
7 Types de données composées
7.1 Traitement des tableaux
Ce qui suit illustre comment on peut définir un tableau PL/SQL nommée g_recip_list (l'information sera utilisée globalement) dans l'exemple de order_total.
TYPE RecipientTabTyp IS TABLE OF NUMBER(22) INDEX BY BINARY_INTEGER; ... g_recip_list RecipientTabTyp;
7.2 Constructions de tableaux
7.3 Traitement des enregistrements
TYPE LineRecTyp IS RECORD (merch_gross NUMBER := 0, recip_num NUMBER := 0 ); ... li_info LineRecTyp;
OPEN c_line_item; ... FETCH c_line_item INTO li_info;
Variables et Constantes
On déclare comme constante une valeur qu'on gardera inchangée tout au long du programme ; au moment de la déclaration on procède comme suit :
Les valeurs qu'on utilise dans un programme proviennent des variables et des constantes qu'on définit au fur et à mesure; les variables, comme le nom l'indique change en fonction de ce qu'on décide à travers les instructions du programme tandis que les contantes non ; quand on parlera de credit_limit dans un programme utilisant la déclaration des constantes faites ci-dessus, on saura que c'est de la valeur "5000.00" qu'on est en train de parler. Avec PL/SQL la déclaration se fait dans la partie reservée à cette effet dans n'importe quel block PL/SQL, sous-programme ou package. La déclaration reserve ainsi un espace mémoire spécifique à chaque type de données . Cette partie est précédée par le mot prédéfini DECLARE comme suit :
Exemples :
DECLARE anniversaire DATE; emp_compt SMALLINT := 0;
Par defaut, si une variable n'est pas initialisée au moment de sa déclaration d'une façon explicite, le système lui assigne la valeur NULL.
Comme on vient de le voir dans l'exemple ci-dessus la déclaration d'une constante a une syntaxe bien précise :
DECLARE ... --- les déclaration qui précident s'il y en a nom_constante CONSTANTTYPE_CONSTANTE := valeur_constante; ... --- les déclarations qui suivent s'il y en a et la suite du programme
blood_type CHAR := 'O';-- est identique à la déclaration ci-dessus blood_type CHAR DEFAULT 'O';
Exemple:
heures_travaillees INTEGER DEFAULT 40; nombre_employees INTEGER := 0;
DECLARE acct_id INTEGER(4) NOT NULL := 9999;
DECLARE
credit PLS_INTEGER RANGE 1000..25000;
debit credit%TYPE;
v_name VARCHAR2(20);
name VARCHAR2(20) NOT NULL := 'Omara Aly';
-- If we increase the length of NAME, the other variables become longer also
upper_name name%TYPE := UPPER(name);
lower_name name%TYPE := LOWER(name);
init_name name%TYPE := INITCAP(name);
BEGIN
-- display inherited default values
DBMS_OUTPUT.PUT_LINE('name: ' || name || ' upper_name: ' || upper_name
|| ' lower_name: ' || lower_name || ' init_name: ' || init_name);
-- lower_name := 'Omara Aly Mohamed'; invalid, character string is too long
-- lower_name := NULL; invalid, NOT NULL CONSTRAINT
-- debit := 50000; invalid, value out of range
END;
/
DECLARE -- If the length of the column ever changes, this code -- will use the new length automatically. the_trigger user_triggers.trigger_name%TYPE;
CREATE TABLE employees_temp (empid NUMBER(6) NOT NULL PRIMARY KEY,
deptid NUMBER(6) CONSTRAINT check_deptid CHECK (deptid BETWEEN 100 AND 200),
deptname VARCHAR2(30) DEFAULT 'Sales');
DECLARE
v_empid employees_temp.empid%TYPE;
v_deptid employees_temp.deptid%TYPE;
v_deptname employees_temp.deptname%TYPE;
BEGIN
v_empid := NULL; -- this works, null constraint is not inherited
-- v_empid := 10000002; -- invalid, number precision too large
v_deptid := 50; -- this works, check constraint is not inherited
-- the default value is not inherited in the following
DBMS_OUTPUT.PUT_LINE('v_deptname: ' || v_deptname);
END;
/
DECLARE
emprec employees_temp%ROWTYPE;
BEGIN
emprec.empid := NULL; -- this works, null constraint is not inherited
-- emprec.empid := 10000002; -- invalid, number precision too large
emprec.deptid := 50; -- this works, check constraint is not inherited
-- the default value is not inherited in the following
DBMS_OUTPUT.PUT_LINE('emprec.deptname: ' || emprec.deptname);
END;
/
DECLARE
-- %ROWTYPE can include all the columns in a table...
emp_rec employees%ROWTYPE;
-- ...or a subset of the columns, based on a cursor.
CURSOR c1 IS
SELECT department_id, department_name FROM departments;
dept_rec c1%ROWTYPE;
-- Could even make a %ROWTYPE with columns from multiple tables.
CURSOR c2 IS
SELECT employee_id, email, employees.manager_id, location_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
join_rec c2%ROWTYPE;
BEGIN
-- We know EMP_REC can hold a row from the EMPLOYEES table.
SELECT * INTO emp_rec FROM employees WHERE ROWNUM < 2;
-- We can refer to the fields of EMP_REC using column names
-- from the EMPLOYEES table.
IF emp_rec.department_id = 20 AND emp_rec.last_name = 'JOHNSON' THEN
emp_rec.salary := emp_rec.salary * 1.15;
END IF;
END;
/
DECLARE dept_rec1 departments%ROWTYPE; dept_rec2 departments%ROWTYPE; CURSOR c1 IS SELECT department_id, location_id FROM departments; dept_rec3 c1%ROWTYPE; BEGIN dept_rec1 := dept_rec2; -- allowed -- dept_rec2 refers to a table, dept_rec3 refers to a cursor -- dept_rec2 := dept_rec3; -- not allowed END; /
DECLARE
dept_rec departments%ROWTYPE;
BEGIN
SELECT * INTO dept_rec FROM departments
WHERE department_id = 30 and ROWNUM < 2;
END;
/
BEGIN
-- We assign an alias (complete_name) to the expression value, because
-- it has no column name.
FOR item IN
( SELECT first_name || ' ' || last_name complete_name
FROM employees WHERE ROWNUM < 11 )
LOOP
-- Now we can refer to the field in the record using this alias.
DBMS_OUTPUT.PUT_LINE('Employee name: ' || item.complete_name);
END LOOP;
END;
/
DECLARE -- la ligne ci-dessus n'est pas valable -- i, j, k, l SMALLINT; -- Instead, declare each separately. -- ce qui suit est valable i SMALLINT; j SMALLINT; -- To save space, you can declare more than one on a line. k SMALLINT; l SMALLINT;
8 Structures de contrôle
8.1 Boucles
<<nom>> LOOP (traitement répétitif) END LOOP nom;
8.2 Boucles WHILE
WHILE (expression) LOOP (traitement de boucle) END LOOP;
8.3 Boucles FOR numériques
<<recip_list>>
FOR i in 1..g_line_counter LOOP (traitement de boucle) END LOOP recip_list;
8.4 Boucles FOR de curseurs
CURSOR c_line_item IS (instruction sql) BEGIN FOR li_info IN c_line_item LOOP (traitement de l'enregistrement extrait) END LOOP; END;
8.5 Structure de contrôle conditionnelle
PROCEDURE
init_recip_list IS recipient_num NUMBER; i BINARY_INTEGER; j BINARY_INTEGER := 1; k BINARY_INTEGER; BEGIN g_out_msg := 'init_recip_list'; <<recip_list>> FOR i in 1..g_line_counter LOOP IF i = 1 THEN g_recip_list(j) := g_recipient_num(i); j := j + 1; g_recip_list(j) := 0; ELSE FOR k in 1..j LOOP IF g_recipient_num(i) = g_recip_list(k) THEN exit; ELSIF k = j THEN g_recip_list(j) := g_recipient_num(i); j := j + 1; 14 g_recip_list(j) := 0; end IF; end LOOP; end IF; end LOOP recip_list; END;
Un autre exemple est l'emploi de EXIT-WHEN qui permet la complétion d'une boucle lorsque certaines conditions sont satisfaites. Considérons l'exemple de sortie de boucle FETCH suivant :
open c_line_item; loop fetch c_line_item into li_info; EXIT WHEN (c_line_item%NOTFOUND) or (c_line_item%NOTFOUND is NULL);
4 Curseurs
4.1 Déclaration de curseurs
CURSOR c_line_item IS (instruction sql)
4.2 Le contrôle d'un curseur
OPEN c_line_item; ... FETCH c_line_item INTO li_info; ... (traitement de la ligne extraite) ... CLOSE c_line_item;
4.3 Attributs des curseurs explicites
{ %NOTFOUND
{ %FOUND
{ %ROWCOUNT
{ %ISOPEN
4.4 Paramétres des curseurs
CURSOR c_line_item (order_num IN NUMBER) IS SELECT merch_gross, recipient_num FROM line_item WHERE order_num = g_order_num;
CURSOR c_line_item (order_num INTEGER DEFAULT 100, line_num INTEGER DEFAULT 1) IS ...
4.5 Création de packages de curseurs
CREATE OR REPLACE PACKAGE order_total AS CURSOR c_line_item RETURN line_item.merch_gross%TYPE; ... END order_total; CREATE OR REPLACE PACKAGE BODY order_total AS CURSOR c_line_item RETURN line_item.merch_gross%TYPE SELECT merch_gross FROM line_item WHERE order_num = g_order_num; ... END order_total;
5 Visibilité des Variables
aspect important d'un langage est la manière de dé.nir les variables. Une fois que les variables sont définies, PL/SQL permet de les utiliser dans des commandes SQL ou dans d'autres commandes du langage. La définition de constantes au sein de PL/SQL suit les mêmes régles. De même, on peut dé.nir des variables et constantes locales à un sous-programme ou globales à un package qui est créé. Il faut dé.nir les variables et les constantes avant de les référencer dans une autre construction.
5.1 Déclaration de variables
5.2 Variables locales
merch_gross NUMBER; recip_count BINARY_INTEGER;
SELECT merch_gross INTO merch_gross FROM line_item WHERE order_num = g_order_num;
5.3 Constantes locales
5.4 Variables globales
CREATE OR REPLACE PACKAGE BODY order_total AS ... g_order_num NUMBER; g_recip_counter BINARY_INTEGER; ... PROCEDURE ...
5.5 Mot-clé DEFAULT
5.6 Attributs des variables et constantes
Nom de la colonne order_num line_num merch_gross recipient_num Donnée 100 1 10.50 1000 Un curseur peut être défini au sein d'une procédure (voir plus haut) a.n d'extraire des informations de la table LINE_ITEM. En même temps que le curseur, on dé.nit une variable ROWTYPE pour stocker les champs de cette ligne comme suit :
CURSOR c_line_item IS SELECT merch_gross, recipient_num FROM line_item WHERE order_num = g_ordnum; li_info c_line_item%ROWTYPE; Pour extraire les données, on utilise FETCH : FETCH c_line_item INTO li_info;
Packages
set echo on spool order_total CREATE OR REPLACE PACKAGE order_total AS (spécifications du package) END order_total CREATE OR REPLACE PACKAGE BODY order_total AS (spécifications du corps du package) END order_total; DROP PUBLIC SYNONYM order_total; CREATE PUBLIC SYNONYM order_total for order_total; GRANT EXECUTE ON order_total TO PUBLIC; spool off SELECT * FROM user_errors WHERE name='ORDER_TOTAL' ;


- Détails
- Catégorie : Oracle
- Affichages : 6599
7 Sources de données ODBC
Sous Windows, un pilote ODBC (Open DataBase Connectivity) sert à masquer aux applications les particularités des bases de données. Ainsi une application Windows pourra utiliser l'interface standard des pilotes ODBC sans se preoccuper de la base de données qui est derriere. Celle-ci peut changer, l'application elle n'aura pas aêtre reecrite. Cette souplesse se paie par une moindre performance vis a vis des pilotes ecrits specialement pour la base de données.
Vous pouvez voir la liste des pilotes ODBC déjà installes sur votre machine par Demarrer/Parametres/Panneau de configuration. L'une des icones du Panneau de configuration est ODBC Data Sources. C'est l'outil de configuration des bases de données ODBC c'est a dire des bases ayant un pilote ODBC. Lorsqu'on ouvre cette application, on obtient un classeur a plusieurs pages dont celui des pilotes ODBC :
Ci-dessus, vous avez la liste des pilotes ODBC installes sur une machine Windows 9x.
7.2 Sources de données ODBC
User DSN
Une source de données ODBC "utilisateur" est donc une source réservée a un utilisateur particulier. Cette notion n'a de sens que sur une machine ayant plusieurs utilisateurs en général NT.
System DSN
Une source de données ODBC "utilisateur" est donc une source connue de tous les utilisateurs d'une machine. Là encore, cette notion a surtout un sens pour NT. File DSN
?
Sur une machine Windows 9x, on choisira User DSN ou System DSN. Il n'y aura une difference que s'il y a plusieurs utilisateurs declares sur la machine. L'interet d'une source de donees ODBC est que les applications windows y ont acces via le nom qu'on lui donne, independamment de son emplacement physique. Cela permet de deplacer physiquement les sources de données sans avoir a reecrire les applications.
7.3 Creer une sources de données ODBC
Faire [Add] pour creer une nouvelle source ODBC.
Il vous faut choisir le pilote ODBC de la source que vous allez construire. Choisissez Microsoft Access driver puis cliquez sur [Terminer]. On obtient ensuite une page d'informations a remplir, page specifique au pilote choisi. Celle d'Access est la suivante :
3 1 2 1 nom de la source - n'est pas forcement le nom de la base ACCESS 2 texte libre de description de la source 3 bouton permettant d'aller designer la base Access qui On fait [OK] pour valider la source qui doit maintenant apparaitre avec les autres dans les sources ODBC "utilisateur". Ces sources peuventêtre supprimees avec le bouton [Remove] et reconfigurees avec le bouton [Configure]. Reconfigurons la source testODBC : et utilisons le bouton [Advanced].On voit ici qu'on pourrait définir un login/mot de passe pour notre source ODBC.
7.4 Utiliser une source de données ODBC
Un panneau "Choisir une source de données" apparait. On y retrouve toutes les sources ODBC. On peut mêmeen creer une nouvelle. Choisissons la source testODBC que nous venons de creer :
Un outil, Microsoft Query est alors lance. Il permet de faire des Requêtes sur des sources ODBC.
Nous retrouvons ci-dessus les trois tables de la base Access test.mdb. Quittons cette fenêtre avec le bouton [Fermer]. puis choisissons l'option Affichage/SQL de Microsoft Query :
Nous avons maintenant une zone dans laquelle nous pouvons saisir une Requête SQL sur la source ODBC :
Lancons l'execution de la Requête ci-dessus par [OK]. La Requête est executee et ses resultats affiches dans MS Query :
Nous pouvons maintenant "exporter" ces resultats vers Excel avec l'option Fichier/Renvoyer les données vers Microsoft Excel : Excel redevient la fenêtre active et demande quoi faire des données qu'il recoit :
Si nous acceptons la proposition ci-dessus, on obtient la feuille Excel suivante :
7.5 Microsoft Query
Il nous faut tout d'abord designer la source de données ODBC qui vaêtre interrogee par Fichier/Nouvelle :
On voit ci-dessus qu'on a aussi la possibilite de creer une nouvelle source de données ODBC si celle-ci n'existait pas encore. Nous avons déjà suivi ce processus pour faire d'une base Access une source de données ODBC. Le processus de creation est ici identique. Choisissons de nouveau la source testODBC :
MS Query nous presente la structure de la source :
On est ramene a l'exemple precedent sur Access qu'on peut refaire ou modifier.
7.6 Echanger des données entre SGBD compatibles ODBC
Une fenêtre demande vers quoi exporter la table t1. Dans type de fichier, choisissez le type "ODBC Bases", pour indiquer que vous allez l'exporter vers une source de données ODBC.
Ce choix fait, il vous est demande vers quelle table vous voulez exporter la table t1. Tapez table1 pour eviter une posible confusion avec la table t1 de la base Access:
Faites [OK].
Ici, il vous est demande de choisir la source de données ODBC ou sera exportee la table t1 d'Access sous le nom table1. Cette source n'existe pas encore.
Faites [New] pour la creer. Demarre alors un assistant de creation :
Indiquez que vous allez creer une source ODBC "utilisateur" et faites [Suivant]. Ensuite, on vous demande quel pilote ODBC voutre source va utiliser. Selectionnez le pilote MySQL :
Faites [Suivant]. Le dernier écran de l'assistant est un recapitulatif des choix faits :
Faites [Terminer]. Le pilote ODBC MySQL prend alors la main pour vous demander de configurer la source :
„« lui donner un nom. Celui-ci est libre
„« indiquer dans quelle base de données, la table Table1 doitêtre creee. Par defaut, le SGBD MySQL vient avec deux bases : test et mysql cette derniere etant réservée a l'administration des bases creees sous MySQL. Nous choisissons donc la base test. La ressemblance avec le nom de la base Access ou le nom de la source ODBC est ici purement fortuit.
„« indiquer sous quel compte (login/mot de passe) la table doit-elleêtre creee.
Faites [OK]. La source de données s'ajoute alors a la liste des sources ODBC déjà existantes : Faites [OK]. Access tente alors une connexion au SGBD MySQL avec les informations qu'on lui a données et represente mêmeune page de connexion a MySQL qui reprend les informations données lors de la configuration de la source de données ODBC :
On pourrait donc ici modifier certaines informations, notamment le login/mot de passe si celui-ci avait change depuis la configuration initiale. Faites simplement [OK]. Et la.... on a une erreur ODBC incomprehensible. Apres de multiples essais, il a fallu se rendre a l'evidence : sur la machine de test, la methode precedente ne fonctionnait pas. Nous l'avons cependant laissee car il se peut que sur votre machine personnelle, cela marche. Si ce n'est pas le cas, vous pouvez essayer la methode suivante. Lancez MS Query et connectez-vous a la source de données ODBC testMYSQL qui vient d'etre creee :
Faites [OK]. La fenêtre de connexion a la source MySQL s'affiche alors.
Faites [OK]. La liste des tables presentes dans la base test de la base mySQL s'affiche alors : Ici, la base etait vide. Ca peutêtre different pour vous. Faites [Fermer] puis prenez l'option Affichage/SQL pour emettre la Requête suivante :
Avec un client MySQL, vous pouvez verifier la creation de la table : mySQL> use test; Database changed mySQL> show tables; +----------------+ | Tables in test | +----------------+ | table1 | +----------------+ 1 row in set (0.05 sec)
Cliquez droit sur un endroi vide de la fenêtre précédente :
à
Choisir testMYSQL. Apparait alors la fenêtre de connexion au SGBD MySQL :
Faites [OK]. Si besoin est, modifiez auparavant le login/mot de passe. La connexion ODBC se fait et les tables de la base ODBC nous sont présentées :
Selectionnez table1 et faites [OK]. La liste des colonnes de table1 est ensuite affichée. Il s'agit de choisir parmi elles celle qui doit jouer le rôle de clé primaire.
Choisissez la colonne id et faites [OK]. La table table1 est alors intégrée a la base test en tant que table attachée : La table table1 ci-dessus n'est qu'une image ACCESS de la table table1 MySQL, seule celle-ci etant reelle. Lorsqu'on modifie l'une, l'autre est modifiee également. Nous allons utiliser cette propriété pour remplir table1 avec le contenu de t1 par un copier/coller entre les deux tables ACCESS ci-dessus. Tout d'abord, verifions la structure de la table attachee table1 : puis son contenu :
Elle est vide. Maintenant copions toutes les lignes de t1 pour les coller dans table1 :
et verifions que les données sont bien arrivees dans la table mySQL table1. Cela peu se faire de plusieurs façons. Avec MS Query, apres s'etre connectee a la base ODBC testMySQL, on emet la Requête suivante :
On obtient le resultat suivant :
Avec le client mysqlc on emet la même Requête :
mySQL> use test Database changed mySQL> show tables; +----------------+ | Tables in test | +----------------+ | table1 | +----------------+ 1 row in set (0.02 sec) mySQL> select * from table1; +------+------+------+ | id | colA | colB | +------+------+------+ | id1 | a1 | 1 | | id2 | a2 | 2 | | id3 | a3 | 3 | | id4 | a4 | 4 | | id5 | a5 | 5 | +------+------+------+ 5 rows in set (0.05 sec) Nous avons donc pu "exporter" des données ACCESS vers une base MySQL.
- Détails
- Catégorie : Oracle
- Affichages : 27602
3 Les expressions du langage SQL
Dans la plupart des commandes SQL, il est possible d'utiliser une expression. Prenons par exemple la commande SELECT dont le syntaxe est le suivant:
SELECT expr1, expr2, ... from table WHERE expression
Exemples
select prix*1.186 from biblio select to_char(achat,'dd/mm/yy') from biblio select titre from biblio where prix between 100 and 150
opérande1 opérateur opérande2 ou fonction (paramètres)
Exemples
Dans l'expression GENRE = 'ROMAN' - GENRE est l'opérande1 - 'ROMAN' est l'opérande2 - = est l'opérateur Dans l'expression to_char(achat,'dd/mm/yy') - TO_CHAR est une fonction - achat et 'dd/mm/yy' sont les parametres de cette fonction.
3.2 Expressions
Nous classifierons les expressions avec opérateur suivant le type de leurs opérandes :
. numerique . chaine de caracteres . date . booleen ou logique
3.2.1.1 Les expressions à opérandes de type numérique
opérateurs relationnels nombre1 > nombre2 : nombre1 plus grand que nombre2 nombre1 >= nombre2 : nombre1 plus grand ou egal a nombre2 Les expressions du langage SQL 35 nombre1 < nombre2 : nombre1 plus petit que nombre2 nombre1 <= nombre2 : nombre1 plus petit ou egal a nombre2 nombre1 = nombre2 : nombre1 egal a nombre2 nombre1 != nombre2 : nombre1 different de nombre2 nombre1 <> nombre2 : idem nombre1 BETWEEN nombre2 AND nombre3 : nombre1 dans l'intervalle [nombre2,nombre3] nombre1 IN (liste de nombres) : nombre1 appartient a liste de nombres nombre1 IS NULL : nombre1 n'a pas de valeur nombre1 IS NOT NULL : nombre1 a une valeur ANY,ALL,EXISTS opérateurs arithmetiques nombre1 + nombre2 : addition nombre1 - nombre2 : soustraction nombre1 * nombre2 : multiplication nombre1 / nombre2 : division
3.2.1.2 opérateurs relationnels
Exemples
SQL> select titre,prix from biblio 2 where prix between 100 and 150; TITRE PRIX ------------------------------------------------------------------- Madame Bovary 136.5 SQL> select titre,prix from biblio 2 where prix not between 100 and 150; TITRE PRIX ------------------------------------------------------------------- Les fleurs du mal 60 Tintin au Tibet 70 La terre 52.5 Manhattan transfer 336 Tintin en Amerique 70 Du cote de ch. Swann 210 Le pere Goriot 200 7 rows selected. SQL> select titre,prix from biblio where prix in (200,210); TITRE PRIX -------------------------------------------------------------------- Du cote de ch. Swann 210 Le pere Goriot 200
3.2.1.3 opérateurs arithmetiques
1 fonctions <---- plus prioritaire 2 () 3 * et / 4 + et - <---- moins prioritaire
Exemple
3.2.2 Les expressions a opérandes de type caracteres
Les opérateurs utilisables sont les suivants :
opérateurs relationnels Soient chaine1, chaine2, chaine3, modele des chaines de caracteres chaine1 > chaine2 : chaine1 plus grande que chaine2 chaine1 >= chaine2 : chaine1 plus grande ou egale a chaine2 chaine1 < chaine2 : chaine1 plus petite que chaine2 chaine1 <= chaine2 : chaine1 plus petite ou egale a chaine2 chaine1 = chaine2 : chaine1 egale a chaine2 chaine1 != chaine2 : chaine1 differente de chaine2 chaine1 <> chaine2 : idem chaine1 BETWEEN chaine2 AND chaine3 : chaine1 dans l'intervalle [chaine2,chaine3] chaine1 IN liste de chaines : chaine1 appartient a liste de chaines chaine1 IS NULL : chaine1 n'a pas de valeur chaine1 IS NOT NULL : chaine1 a une valeur chaine1 LIKE modele : chaine1 correspond a modele ANY,ALL,EXISTS opérateurs de concatenation chaine1 || chaine2 : chaine2 concatenee a chaine1
3.2.2.2 opérateurs relationnels
Tout caractere est code sur un octet par un nombre compris entre 0 et 255. On appelle ce codage, le code ASCII des caracteres. On trouvera ces codes ASCII en annexe. Ce codage permet la comparaison entre deux caracteres. Ce sont en effet les codes ASCII (des nombres donc) des caracteres qui sont compares. Ainsi on dira que le caractere C1 est plus petit que le caractere C2 si le code ASCII de C1 est plus petit que le code ASCII de C2. A partir de la table des codes ASCII, on a les relations suivantes :
blanc<..< 0 < 1 < ...< 9 < ...< A <B <... < Z < ... < a < b < ... < z Dans l'ordre ASCII, les chiffres viennent avant les lettres, et les majuscules avant les minuscules. On remarquera que l'ordre ASCII respecte l'ordre des chiffres ainsi que l'ordre alphabetique auquel on est habitue.
3.2.2.3 Comparaison de deux chaines
Pour effectuer cette comparaison, ORACLE compare les deux chaines caractere par caractere sur la base de leurs codes ASCII. Des que deux caracteres sont trouves differents, la chaine a qui appartient le plus petit des deux est dite plus petite que l'autre chaine. Dans notre exemple 'CHAT' est comparee a 'CHIEN'. On a les resultats successifs suivants :
'CHAT' 'CHIEN' --------------------------------------------------------------------- 'C' = 'C' 'H' = 'H' 'A' < 'I' Apres cette derniere comparaison, la chaine 'CHAT' est declaree plus petite que la chaine 'CHIEN' dans l'ordre ASCII. La relation 'CHAT' < 'CHIEN' est donc vraie. Soit a comparer maintenant 'CHAT' et 'chat'. 'CHAT' 'chat' --------------------------------------------------------------------- 'C' < 'c'
Exemples
SQL> select titre from biblio; TITRE ------------------------------------------------------------------ Les fleurs du mal Tintin au Tibet La terre Madame Bovary Manhattan transfer Tintin en Amerique Du cote de ch. Swann Le pere Goriot 8 rows selected. SQL> select titre from biblio where upper(titre) between 'L' and 'U'; TITRE ------------------------------------------------------------------------------ Les fleurs du mal Tintin au Tibet La terre Madame Bovary Manhattan transfer Les expressions du langage SQL 38 Tintin en Amerique Le pere Goriot 7 rows selected.
3.2.2.4 L'opérateur LIKE
le symbole "%" qui designe toute suite de caracteres le symbole "_" qui designe 1 caractere quelconque
Exemples
SQL> select titre from biblio; TITRE ------------------------------------------------------------------ Les fleurs du mal Tintin au Tibet La terre Madame Bovary Manhattan transfer Tintin en Amerique Du cote de ch. Swann Le pere Goriot 8 rows selected. SQL> select titre from biblio where titre like 'M%'; TITRE ------------------------------------------------------------------ Madame Bovary Manhattan transfer
SQL> select titre from biblio where titre like 'L_ %'; TITRE ------------------------------------------------------------------ La terre Le pere Goriot
3.2.2.5 L'opérateur de concatenation
SQL> select 'chat'||'eau'
Exemple from dual; <-- concatenation de 'chat' avec 'eau'
Exemples
-------------------------------------------------------------------- chateau <-- résultat de la concaténation
3.2.3 Les expressions a opérandes de type date
Soient date1, date2, date3 des dates. Les opérateurs utilisables sont les suivants : opérateurs relationnels date1 < date2 est vraie si date1 est anterieure a date2 date1 <= date2 est vraie si date1 est anterieure ou egale a date2 date1> date2 est vraie si date1 est posterieure a date2 Les expressions du langage SQL 39 date1>= date2 est vraie si date1 est posterieure ou egale a date2 date1 = date2 est vraie si date1 et date2 sont identiques date1 <> date2 est vraie si date1 et date2 sont differentes. date1 != date2 idem date1 BETWEEN date2 AND date3 est vraie si date1 est situe entre date2 et date3 date1 IN (liste de dates) est vraie si date1 se trouve dans la liste de dates date1 IS NULL est vraie si date1 n'a pas de valeur date1 IS NOT NULL est vraie si date1 a une valeur date1 LIKE modele est vraie si date1 correspond au modele ALL,ANY,EXISTS opérateurs arithmetiques date1 - date2 : nombre de jours séparant date1 de date2 date1 - nombre : date2 telle que date1-date2=nombre date1 + nombre : date2 telle que date2-date1=nombre
Exemples
SQL> select achat from biblio; ACHAT --------- 01-JAN-78 10-NOV-90 12-JUN-90 12-MAR-88 30-AUG-87 15-MAY-91 08-DEC-78 01-SEP-91 8 rows selected. SQL> select achat from biblio where achat between '01-jan-88' and '31-dec-88'; ACHAT --------- 12-MAR-88 SQL> select achat from biblio where achat like '__-MA%'; ACHAT --------- 12-MAR-88 15-MAY-91 SQL> select sysdate from dual;<-- date & heure du moment SYSDATE --------- 18-OCT-91 SQL> select sysdate-achat age from biblio; <-- age des livres ? AGE ---------- 5038.63328 <-- les chiffres derrière le point correspondent a la composante heure de la date 342.633275 493.633275 1315.63328 1510.63328 156.633275 4697.63328 47.6332755 8 rows selected. SQL> select trunc(sysdate-achat) age from biblio; <-- trunc pour enlever la composante heure AGE ---------- 5038 342 493 1315 1510 156 4697 47 8 rows selected.
3.2.4 Expressions à opérandes booleennes
Soient booleen1 et booleen2 deux booleens. Il y a trois opérateurs possibles qui sont par ordre de priorité : booleen1 AND booleen2 est vraie si booleen1 et booleen2 sont vrais tous les deux. booleen1 OR booleen2 est vraie si booleen1 ou booleen2 est vrai. NOT booleen1 a pour valeur l'inverse de la valeur de booleen1.
Exemples
SQL> select titre,genre,prix from biblio; TITRE GENRE PRIX -------------------- --------------- ---------- Les fleurs du mal POEME 60 Tintin au Tibet BD 70 La terre ROMAN 52.5 Madame Bovary ROMAN 136.5 Manhattan transfer ROMAN 336 Tintin en Amerique BD 70 Du cote de ch. Swann ROMAN 210 Le pere Goriot ROMAN 200 8 rows selected. SQL> select titre,genre,prix from biblio where prix>=50 and prix <=100; TITRE GENRE PRIX -------------------- ----------- ------ Les fleurs du mal POEME 60 Tintin au Tibet BD 70 La terre ROMAN 52.5 Tintin en Amerique BD 70 SQL> select titre,genre,prix from biblio 2 where prix <50 or prix >100; TITRE GENRE PRIX -------------------- --------------- ---------- Madame Bovary ROMAN 136.5 Manhattan transfer ROMAN 336 Du cote de ch. Swann ROMAN 210 Le pere Goriot ROMAN 200 SQL> select titre,genre,prix from biblio 2 where genre='ROMAN' and prix>200 or prix<100; <-- attention a la priorite des opérateurs TITRE GENRE PRIX -------------------- --------------- ---------- Les fleurs du mal POEME 60 Tintin au Tibet BD 70 La terre ROMAN 52.5 Manhattan transfer ROMAN 336 Les expressions du langage SQL 41 Tintin en Amerique BD 70 Du cote de ch. Swann ROMAN 210 6 rows selected. SQL> select titre,genre,prix from biblio 2* where genre='ROMAN' and (prix>200 or prix<100) <-- on met des parentheses TITRE GENRE PRIX -------------------- --------------- ---------- La terre ROMAN 52.5 Manhattan transfer ROMAN 336 Du cote de ch. Swann ROMAN 210
3.3 Les fonctions prédéfinies d'ORACLE
. fonctions a parametres de type numerique . fonctions a parametres de type chaine de caracteres . fonctions a parametres de type date . fonctions de conversion de type . fonctions diverses
la fonction est evaluee le plus souvent pour chaque ligne de la table. On a donc affichage de n resultats pour n lignes. Certaines fonctions cependant, sont evaluees a partir des données de toutes les lignes de la table et ne donnent lieu qu'a un seul resultat. On les appellera des fonctions de groupe. On les connait pour la plupart : ce sont les fonctions statistiques COUNT, SUM, AVG, STDDEV, VARIANCE, MAX, MIN.
Le lecteur pourra tester les fonctions presentees ci-apres par la commande :
SELECT fonction FROM DUAL La table DUAL comme il a été déjà explique est une table a une ligne et une colonne qui contient l'unique donnee 'X'.
SQL> describe dual; Name Null? Type ----------------- -------- ---- DUMMY CHAR(1) <-- une seule colonne de type caractere SQL> select * from dual; <-- contenu de la table DUAL D-X <-- une seule ligne La commande SELECT fonction FROM DUAL evalue fonction pour chaque ligne de la table DUAL, donc en fait pour une seule ligne. Il y a donc simplement affichage de la valeur de fonction.
3.3.1 Fonctions a parametres de type numerique
abs(nombre) valeur absolue de nombre abs(-15)=15 ceil(nombre) plus petit entier plus grand ou egal a nombre ceil(15.7)=16 Les expressions du langage SQL 42 floor(nombre) plus grand entier inferieur ou egal a nombre floor(14.3)=14 mod(nombre1,nombre2) reste de la division entiere (le quotient est entier) de nombre1 par nombre2 mod(7,3)=1 mod(7.5,3.2)=1.1 power(nombre1,nombre2) nombre1 eleve a la puissance nombre2 qui doitêtre entier power(4,2)=16 round(nombre1,nombre2) arrondit nombre1 a nombre2 chiffres apres la virgule si nombre2>0, a -nombre2 chiffres avant la virgule si nombre2<0. round(13.456,2)=13.46 round(13.456,-1)=10 round(16.456,-1)=20 round(16.456,0)=16 sign(nombre) -1 si nombre<0 0 si nombre=0 +1 si nombre>0 sign(-6)=-1 sqrt(nombre) racine carree de nombre si nombre>=0 NULL si nombre<0 sqrt(16)=4 trunc(nombre1,nombre2) nombre1 est tronque a nombre2 chiffres apres la virgule si nombre2>0 ou a -nombre2 chiffres avant la virgule si nombre2<0. trunc(13.456,2)=13.45 trunc(13.456,-1)=10 trunc(16.456,-1)=10 trunc(16.456,0)=16
3.3.2 Fonctions a parametres de type chaine de caracteres
chr(nombre) caractere de code ASCII nombre
chr(65)='A'
initcap(chaine) Met tous les mots de chaine en minuscules
sauf la premiere lettre mise en majuscule
initcap ('gestion des stocks')='Gestion Des Stocks'
lower(chaine) met chaine en minuscules
lower('INFO')='info'
lpad(chaine1,n,chaine2) met chaine1 sur n positions, chaine1
etant cadree a droite. Les caracteres restant a gauche sont remplis par
chaine2.
lpad('chat',6,'*')='**chat'
lpad('chat,8,'xy')='xyxychat'
ltrim(chaine1,chaine2) Les caracteres de gauche
de chaine1 sont supprimes jusqu'a rencontrer un caractere qui ne se trouve pas
dans chaine2.
ltrim('chaton','ch')='aton'
ltrim('chaton','hc')='aton'
ltrim('chaton','abc')='haton'
replace(chaine1,chaine2,chaine3) remplace chaine2 par chaine3 dans chaine1.
replace('chat et chien','ch','**')='**at et **ien'
rpad(chaine1,n,chaine2) idem lpad mais a droite
rpad('chat',6,'*')='chat**'
rpad('chat,8,'xy')='chatxyxy'
trim(chaine1,chaine2) idem ltrim mais a droite
rtrim('chat','at')='ch'
rtrim('chat','ta')='ch'
Les expressions du langage SQL 43
substr(chaine,p,nombre) sous-chaine de chaine
de nombre caracteres commencant en position p.
substr('chaton',3,2)='at'
translate(chaine,texte,traduction) remplace dans chaine
tout caractere se trouvant dans texte par le caractere correspondant se trouvant dans
traduction
translate('abracadabra,'ab','yz')='yzrycydyzry'
ascii(caractere) code ASCII de caractere
ascii('A')=65
instr(chaine1,chaine2,p,o) position de la o ieme occurrence
de chaine2 dans chaine1, la recherche commencant a la position p de
chaine1.
instr('abracadabra','a',4,2)=6
instr('abracadabra','a',5,3)=11
length(chaine) nombre de caracteres de chaine
length('chaton')=6
3.3.3 Fonctions de conversion
to_char(nombre,format) transforme nombre en chaine de caracteres selon le format indique.
Les formats utilisables sont ceux déjà presentes.
to_char(1000,'99999.99')=' 1000.00'
to_char(1000,'99EEEE')=' 1E+03'
to_char(date,format) convertit date en chaine de caracteres
selon le format indique. Cette fonction a été déjà presentee.
to_date(chaine,format) transforme chaine en date.
Le format decrit la chaine. Les differents formats utilisables ont déjà été presentes.
SQL> select to_date ('01/02/91' , 'dd/mm/yy') from dual;
TO_DATE('
-----------------------------------------------------------------------------------
01-FEB-91
SQL> select to_date('01 january 91','dd month yy') from dual;
TO_DATE('
-----------------------------------------------------------------------------------
01-JAN-91
to_number(chaine) transforme chaine en nombre.
Il faut pour cela que chaine represente un nombre valide.
to_number('1987')=1987
3.3.4 Fonctions de parametres de type date
addate(date,n) date augmentee de n mois. Le resultat est une date.
date('01-jan-91',3)='01-apr-91'
last_day(date) date du dernier jour du mois contenu dans date
last_day('01-jan-91')='31-jan-91'
months_between(date1,date2) nombre de mois entre date1 et date2.
La partie decimale represente le pourcentage d'un mois de 31 jours.
Si date1<date2 le resultat est >0 sinon il est <0.
month_between('01-jan-91','14-feb-91')=-1.4193548
next_day(date,jour) donne la date du jour indique dans la semaine qui suit date.
next_day('01-jan-91','monday')='07-jan-91'
sysdate date du jour maintenue par le système
Les expressions du langage SQL 44
round(date,format) date arrondie selon le format precise
Formats
year : arrondit au 1er janvier le plus proche
month : arrondit au 1er du mois le plus proche
day : arrondit au dimanche le plus proche
Exemples
select sysdate from dual; SYSDATE --------- 21-OCT-91 SQL> select round(sysdate,'year') from dual; ROUND(SYS --------- 01-JAN-92 SQL> select round(sysdate,'month') from dual; ROUND(SYS --------- 01-NOV-91 SQL> select round(sysdate,'day') from dual; ROUND(SYS --------- 20-OCT-91 trunc(date,[format]) tronque date selon le format indique. Par defaut, c'est la composante heure qui est supprimee. Formats year : tronque au 1er janvier de l'annee de date month : tronque au 1er du mois de date day : tronque au dimanche qui precede date.
Exemples
SQL> select sysdate from dual; SYSDATE --------- 21-OCT-91 SQL> select trunc(sysdate,'year') from dual; TRUNC(SYS --------- 01-JAN-91 SQL> select trunc(sysdate,'month') from dual TRUNC(SYS --------- 01-OCT-91 SQL> select trunc(sysdate,'day') from dual TRUNC(SYS --------- 20-OCT-91
3.3.5 Fonctions a parametres de type variable
Exemples
SQL> select greatest(100,200,300) grand, least(100,200,300) petit from dual
GRAND PETIT
--------------------
300 100
SQL> select greatest('chat','chien','veau') grand, least('chat','chien','veau')
petit from dual;
GRAND PETIT
-------------------
veau chat
SQL> select greatest('01-jan-91','10-feb-91','15-sep-87') grand, least
('01-jan-91', '10-feb-91', '15-sep-87') petit from dual;
GRAND PETIT
-------------------
15-sep-87 01-jan-91
SQL> select greatest(to_date('01-jan-91'), to_date('10-feb-91'),to_date('15-sep-87')) grand,
least(to_date('01-jan-91'), to_date('10-feb-91'),to_date('15-sep-87')) petit from dual
GRAND PETIT
------------------
10-FEB-91 15-SEP-87
3.3.6 Fonctions diverses
user nom de connexion Oracle de l'utilisateur uid n¢X identifiant chaque utilisateur Oracle userenv(option) options 'terminal' : identificateur du terminal de l'utilisateur 'language' : identificateur de la langue utilisee par Oracle
Exemples
SQL> select user,uid,userenv('terminal'),userenv('language') from dual;
USER UID USERENV( USERENV('LANGUAGE')
---------------------------------------------------
omara 9 ttyc3d13 AMERICAN_AMERICA.US7ASCII
4 Approfondissement du langage SQL
Dans ce chapitre nous voyons
.d'autres syntaxes de la commande SELECT qui en font une commande de consultation tres puissante notamment pour consulter plusieurs tables a la fois.
. des syntaxes elargies de commandes déjà etudiees
. les commandes de gestion de la securite des données.
. Les commandes de gestion des performances des Requêtes
Pour illustrer les diverses commandes etudiees, nous travaillerons avec les tables suivantes utilisees pour la gestion des commandes dans une PME de diffusion de livres :
la table CLIENTS :
Elle memorise des informations sur les clients de la PME. Sa structure est la suivante :
NOM - char(30) : nom du client STATUT - char(1) : I=Individu, E=Entreprise, A=Administration PRENOM - char(20) : prenom dans le cas d'un individu CONTACT - char(30) : Nom de la personne a contacter chez le client (dans le cas d'une entreprise ou d'une administration) RUE - char(25) : Adresse du client - rue VILLE - char(20) : ville CPOSTAL - char(5) : code postal TELEPH - char(20) : Telephone DEPUIS - date : Client depuis quelle date ? IDCLI - char(6) : n¢X identifiant le client de facon unique DEBITEUR - char(1) : O (Oui) si le client doit de l'argent a l'entreprise et N (Non) sinon.
Exemple
NOM : LIBRAIRIE LA NACELLE STATUT : E PRENOM : CONTACT : Catherine Duchemin RUE : 115,Bd du Montparnasse VILLE : PARIS CPOSTAL : 75014 TELEPH : 16-1-45-56-67-78 DEPUIS : 06-APR-81 IDCLI : 001006 Conclusion 47 DEBITEUR : N la table STOCKS
ISBN - char(13) : nº identifiant un livre de facon unique (ISBN= International Standard Book Number)
TITRE - char(30) : Titre du livre CODEDITEUR - char(7) : Code identifiant un editeur de facon unique AUTEUR - char(30) : nom de l'auteur RESUME - char(400) : resume du livre QTEANCOUR - number(4) : Quantite vendue dans l'annee QTEANPREC - number(4) : Quantite vendue l'annee precedente DERNVENTE - date : date de la derniere vente QTERECUE - number(3) : Quantite de la derniere livraison DERNLIV - date : Date de la derniere livraison PRIXVENTE - number(6,2) : Prix de vente COUT - number(6,2) : Cout d'achat MINCDE - number(3) : Quantite minimale a commander MINSTOCK - number(3) : Seuil minimal du stock QTESTOCK - number(3) : Quantite en stock
Exemple
ISBN : 0-913577-03-1 TITRE : La gestion avec DBASE III Plus CODEDITEUR : 104 AUTEUR : BYERS RESUME : QTEANCOUR : 32 QTEANPREC : 187 DERNVENTE : 08-AUG-89 QTERECUE : 40 DERNLIV : 07-JUL-89 PRIXVENTE : 350 COUT : 280 MINCDE : 20 MINSTOCK : 10 QTESTOCK : 32 la table COMMANDES
NOCMD - number(6) : Nº identifiant une commande de facon unique IDCLI - char(6) : Nº du client faisant cette commande ( cf fichier CLIENTS) DATE_CMD - date : Date de saisie de cette commande ANNULE - char(1) : O (Oui) si la commande a été annulee et N (Non) sinon.
Exemple
NOCMD : 100204 IDCLI : 001006 DATE : 15-AUG-89 ANNULE : N
Elle contient les details d'une commande, c'est a dire les references et quantites des livres commandes. Sa structure est la suivante :
NOCMD - number(6) : Nº de la commande (cf fichier COMMANDES) ISBN - char(13) : nº du livre commande ( cf fichier STOCKS) QTE - number(3) : Quantite commandee
Exemple :
NOCMD ISBN QTE 100204 0-912677-45-7 100 100204 0-912677-16-3 50 Leur contenu est le suivant : SQL> select nom,statut,ville,cpostal,depuis,idcli,debiteur from clients; NOM S VILLE CPOST DEPUIS IDCLI D LIBRAIRIE LA COMété E ANGERS 49000 01-MAR-88 000001 N LIBRAIRIE DU MARCHE E ANGERS 49100 01-APR-89 000002 O TRESOR PUBLIC A ANGERS 49000 01-JAN-87 000003 N MAIRIE D'ANGERS A SAUMUR 49700 01-FEB-78 000004 O TELELOGOS E SEGRE 49500 01-OCT-77 000005 N BARNARD I CHOLET 49800 01-SEP-77 000006 N PREFECTURE DU M & L A ANGERS 49000 10-DEC-66 000007 O ARTUS E AVRILLE 49350 14-JUN-88 000008 N MECAFLUID E SAUMUR 49550 23-JUL-90 000009 N PLUCHOT I SEGRE 49100 21-FEB-89 000010 O 10 rows selected. SQL> select isbn,titre,qteancour,qteanprec,dernvente,qterecue 2 prixvente,cout,mincde,minstock,qtestock from stocks; ISBN TITRE QTEAN COUR QTEAN PREC DERNV ENTE QTERE CUE PRIXV ENTE CO UT MIN CDE MINST OCK QTEST OCK 0-07-881551-7 DVORAK'S GUIDE TOO TELECOM 100 500 14- FEB- 90 50 250 20 0 50 20 100 0-07-881309-3 USING 1-2-3 RELEASE 3 1000 5000 01- AUG- 91 100 200 18 0 100 30 430 0-07-881524-X USING SQL 800 1000 06- SEP- 91 40 320 25 0 50 30 210 0-07-881497-9 DOS - THE COMPLété REFERENCE 670 8000 14- SEP- 91 500 340 27 0 100 100 780 0-07-881520-7 USING QUICK PASCAL 150 600 14- SEP- 91 80 280 23 0 40 40 200 0-07-881537-1 USING WINDOWS 3 45 0 18- SEP- 91 50 450 40 0 30 15 67 6 rows selected. SQL> select * from commandes; NOCMD IDCLI DATE_CMD A 1 000003 21-SEP-91 N 2 000002 21-SEP-91 N 3 000005 23-SEP-91 N 4 000006 24-SEP-91 N 5 000002 25-SEP-91 N 7 000004 25-SEP-91 N 9 000005 26-SEP-91 N 10 000003 26-SEP-91 N SQL> select * from articles; NOCMD ISBN QTE 1 0-07-881551-7 2 1 0-07-881524-X 1 2 0-07-881537-1 4 3 0-07-881520-7 1 3 0-07-881551-7 1 3 0-07-881497-9 4 4 0-07-881551-7 2 4 0-07-881309-3 4 5 0-07-881309-3 1 7 0-07-881551-7 1 9 0-07-881524-X 3 10 0-07-881497-9 12 10 0-07-881520-7 2
4.2 La commande SELECT
4.2.2 La jointure entre deux tables
Soient deux tables table1 et table2. table1 a les colonnes col1 et col2 et table2 les colonnes cola, colb. Supposons que le contenu des tables soit le suivant :
table1 col1 col2 x 3 y 4 table2 cola colb a 7 b 4 Soit la commande : SELECT col1, cola FROM table1, table2 WHERE table1.col2=table2.colb
Une nouvelle table est construite avec pour colonnes, l'ensemble des colonnes des deux tables et pour lignes le produit cartesien des deux tables :
col1 col2 cola colb x 3 a 7 x 3 b 4 y 4 a 7 y 4 b 4
col1 col2 cola colb y 4 b 4 Il y a ensuite affichage des colonnes demandees : col1 cola y b
4.2.2.1 Syntaxe d'une Requête multi-tables
syntaxe SELECT colonne1, colonne2, ... FROM table1, table2, ..., tablep WHERE condition ORDER BY ...
Fonctionnement
1 La table produit cartesien de table1, table2, ..., tablep est realisee. Si ni est le nombre de lignes de tablei, la table construite a donc n1*n2*...*np lignes comportant l'ensemble des colonnes des differentes tables.
2 La condition du WHERE est appliquee a cette table. Une nouvelle table est ainsi produite
3 Celle-ci est ordonnee selon le mode indique dans ORDER.
4 Les colonnes demandees derriere SELECT sont affichees.
Exemples
SQL> 1 select articles.nocmd,isbn,qte from commandes,articles 2 where date_cmd>'25-sep-91' 3 and articles.nocmd=commandes.nocmd; NOCMD ISBN QTE ---------- ------------- ---------- 9 0-07-881524-X 3 10 0-07-881497-9 12 10 0-07-881520-7 2
Continuons nos exemples. On desire le mêmeresultat que precedemment mais avec le titre du livre commande plutot que son nº ISBN :
SQL> 1 select commandes.nocmd, stocks.titre, qte 2 from commandes,articles,stocks 3 where date_cmd>'25-sep-91' 4 and articles.nocmd=commandes.nocmd 5 and articles.isbn=stocks.isbn NOCMD TITRE QTE -------------------------------------------------------------------------- 9 USING SQL 3 10 DOS - THE COMPLété REFERENCE 12 10 USING QUICK PASCAL 2 On veut de plus le nom du client qui fait la commande : SQL> 1 select commandes.nocmd, stocks.titre, qte ,clients.nom 2 from commandes,articles,stocks,clients 3 where date_cmd>'25-sep-91' 4 and articles.nocmd=commandes.nocmd 5 and articles.isbn=stocks.isbn 6 and commandes.idcli=clients.idcli; NOCMD TITRE QTE NOM ----------------------------------- ------ ------------------------------ 10 DOS - THE COMPLété REFERENCE 12 TRESOR PUBLIC 10 USING QUICK PASCAL 2 TRESOR PUBLIC 9 USING SQL 3 TELELOGOS
SQL> 1 select commandes.nocmd, date_cmd, stocks.titre, qte ,clients.nom 2 from commandes,articles,stocks,clients 3 where date_cmd>'25-sep-91' 4 and articles.nocmd=commandes.nocmd 5 and articles.isbn=stocks.isbn 6 and commandes.idcli=clients.idcli 7 order by date_cmd desc; NOCMD DATE_CMD TITRE QTE NOM ----------------------------------------------------------------------------- 10 26-SEP-91 DOS - THE COMPLété REFERENCE 12 TRESOR PUBLIC 10 26-SEP-91 USING QUICK PASCAL 2 TRESOR PUBLIC 9 26-SEP-91 USING SQL 3 TELELOGOS
1 Derriere SELECT, on met les colonnes que l'on desire obtenir a l'affichage. Si la colonne existe dans diverses tables, on la fait preceder du nom de la table.
2 Derriere FROM, on met toutes les tables qui seront explorees par le SELECT, c'est a dire les tables proprietaires des colonnes qui se trouvent derriere SELECT et WHERE.
SQL> 1 select a.titre from stocks a, stocks b 2 where b.titre='USING SQL' 3 and a.prixvente>b.prixvente TITRE ------------------------------------------------------------------------ DOS - THE COMPLété REFERENCE USING WINDOWS 3
4.2.2.3 Jointure externe
SELECT col1, cola FROM table1, table2 WHERE table1.col2=table2.colb
SELECT col1, cola FROM table1, table2 WHERE table1.col2=table2.colb (+)
SELECT col1, cola FROM table1, table2 WHERE table1.col2(+)=table2.colb
Exemples :
SQL> 1 select nom,date_cmd from clients,commandes 2 where date_cmd between '01-sep-91' and '30-sep-91' 3* and clients.idcli=commandes.idcli (+) NOM DATE_CMD ------------------------------------------------------------- LIBRAIRIE DU MARCHE 21-SEP-91 LIBRAIRIE DU MARCHE 25-SEP-91 TRESOR PUBLIC 21-SEP-91 TRESOR PUBLIC 26-SEP-91 MAIRIE D'ANGERS 25-SEP-91 TELELOGOS 23-SEP-91 TELELOGOS 26-SEP-91 BARNARD 24-SEP-91
SQL> 1 select nom,date_cmd from clients,commandes 2 where ( date_cmd between '01-sep-91' and '30-sep-91' 3 or date_cmd is null) 4* and clients.idcli=commandes.idcli (+) NOM DATE_CMD ------------------------------------------ LIBRAIRIE LA COMété LIBRAIRIE DU MARCHE 21-SEP-91 LIBRAIRIE DU MARCHE 25-SEP-91 TRESOR PUBLIC 21-SEP-91 TRESOR PUBLIC 26-SEP-91 MAIRIE D'ANGERS 25-SEP-91 TELELOGOS 23-SEP-91 TELELOGOS 26-SEP-91 BARNARD 24-SEP-91 PREFECTURE DU M & L ARTUS MECAFLUID PLUCHOT
SQL> 1 select nom,date_cmd from clients,commandes 2 where ( date_cmd between '01-sep-91' and '30-sep-91' 3 or date_cmd is null) 4 and clients.idcli (+)=commandes.idcli
syntaxe SELECT colonne[s] FROM table[s] WHERE expression opérateur Requête ORDER BY ...
expression opérateur valeur que nous connaissons bien. Si la Requête delivre une liste de valeurs, on pourra employer les opérateurs suivants :
IN expression IN (val1, val2, ..., vali) vraie si expression a pour valeur l'un des éléments de la liste vali. NOT IN inverse de IN ANY doit être precede de =,!=,>,>=,<,<= expression >= ANY (val1, val2, .., valn) vraie si expression est >= a l'une des valeurs vali de la liste ALL doitêtre precede de =,!=,>,>=,<,<= expression >= ALL (val1, val2, .., valn) vraie si expression est >= a toutes les valeurs valide la liste EXISTS Requête vraie si la Requête rend au moins une ligne.
Exemples
SQL> 1 select titre from stocks 2 where prixvente > (select prixvente from stocks where titre='USING SQL') TITRE ------------------------------ DOS - THE COMPLété REFERENCE USING WINDOWS 3
SQL> 1 select titre from stocks 2 where prixvente > (select avg(prixvente) from stocks) TITRE ------------------------------ USING SQL DOS - THE COMPLété REFERENCE USING WINDOWS 3 Quels sont les clients ayant commande les titres resultat de la Requête precedente ? SQL> 1 select distinct idcli from commandes ,articles 2 where articles.isbn in (select isbn from stocks where prixvente 3 > (select avg(prixvente) from stocks)) 4 and commandes.nocmd=articles.nocmd IDCLI ------ 000002 000003 000005
Explications
b dans les lignes selectionnees de la table articles, il n'y a pas le code client IDCLI. Il se trouve dans la table commandes. Le lien entre les deux tables se fait par le n¢X de commande nocmd, d'ou l'equi-jointure commandes.nocmd = articles.nocmd.
c Un mêmeclient peut avoir achété plusieurs fois l'un des livres concernes, auquel cas on aura son code IDCLI plusieurs fois. Pour eviter cela, on met le mot cle DISTINCT derriere SELECT.
d pour avoir le nom du client, il nous faudrait faire une equi-jointure supplementaire entre les tables commandes et clients.
Trouver les clients qui n'ont pas fait de commande depuis le 24 septembre :
SQL> 1 select nom from clients 2 where clients.idcli not in (select distinct commandes.idcli 3 from commandes where date_cmd>='24-sep-91') NOM ------------------------------ LIBRAIRIE LA COMété PREFECTURE DU M & L ARTUS MECAFLUID PLUCHOT
HAVING expression opérateur Requête
est possible, avec la contrainte déjà presentee que expression doitêtre l'une des expressions expri de la clause GROUP BY expr1, expr2, ...
Exemples
Sortons d'abord les quantites vendues par titre :
SQL> 1 select titre,sum(qte) from stocks, articles 2 where articles.isbn=stocks.isbn 3 group by titre TITRE SUM(QTE) --------------------- ---------- DOS - THE COMPLété REFERENCE 16 DVORAK'S GUIDE TOO TELECOM 6 USING 1-2-3 RELEASE 3 5 USING QUICK PASCAL 3 USING SQL 4 USING WINDOWS 3 4 Maintenant, filtrons les titres : SQL> 1 select titre,sum(qte) from stocks,commandes,articles 2 where articles.isbn=stocks.isbn 3 group by titre 4 having titre in (select titre from stocks where prixvente>200) TITRE SUM(QTE) --------------------- ---------- DOS - THE COMPLété REFERENCE 16 DVORAK'S GUIDE TOO TELECOM 6 USING QUICK PASCAL 3 USING SQL 4 USING WINDOWS 3 4 De facon peut-etre plus evidente on aurait pu ecrire : SQL> 1 select titre,sum(qte) from stocks,commandes,articles 2 where articles.nocmd=commandes.nocmd Conclusion 56 3 and articles.isbn=stocks.isbn 4 and prixvente>200 5* group by titre TITRE SUM(QTE) --------------------- ---------- DOS - THE COMPLété REFERENCE 16 DVORAK'S GUIDE TOO TELECOM 6 USING QUICK PASCAL 3 USING SQL 4 USING WINDOWS 3 4
4.2.4 Requêtes corrélées
Exemple :
SQL> 1 select nom from clients 2 where not exists 3 (select idcli from commandes 4 where date_cmd>='24-sep-91' 5 and commandes.idcli=clients.idcli) NOM ------------------------------ LIBRAIRIE LA COMETE PREFECTURE DU M & L ARTUS MECAFLUID PLUCHOT
4.2.5 Criteres de choix pour l'ecriture du SELECT
Exemple :
Afficher les clients ayant commande quelque chose :
Jointure SQL> 1 select distinct nom from clients,commandes 2 where clients.idcli=commandes.idcli NOM ------------------------------------------------------------------- BARNARD LIBRAIRIE DU MARCHE MAIRIE D'ANGERS TELELOGOS TRESOR PUBLIC Requêtes IMBRIQUEES
SQL> 1 select nom from clients 2 where idcli in (select idcli from commandes) NOM ------------------------------------------------------------------------------ LIBRAIRIE DU MARCHE TRESOR PUBLIC MAIRIE D'ANGERS TELELOGOS BARNARD Requêtes CORRELEES
SQL> 1 select nom from clients 2 where exists (select * from commandes where commandes.idcli=clients.idcli) NOM ------------------------------------------------------------------------------- LIBRAIRIE DU MARCHE TRESOR PUBLIC MAIRIE D'ANGERS TELELOGOS BARNARD
Performances
L'utilisateur ne sait pas comment ORACLE "se debrouille" pour trouver les resultats qu'il demande. Ce n'est donc que par experience, qu'il decouvrira que telle ecriture est plus performante qu'une autre. MAREE et LEDANT affirment par experience que les Requêtes correlees semblent généralement plus lentes que les Requêtes imbriquees ou les jointures. FORMULATION La formulation par Requêtes imbriquees est toujours plus lisible et plus intuitive que la jointure. Elle n'est cependant pas toujours utilisable. La regle est simple : Les tables proprietaires des colonnes arguments du SELECT ( SELECT col1, col2, ...) doivent être nommées derrière FROM. Le produit cartesien de ces tables est alors effectue, ce qu'on appelle une jointure. Lorsque la Requête affiche des resultats provenant d'une seule table, et que le filtrage des lignes de cette dernière impose la consultation d'une autre table, les Requêtes imbriquées s'imposent.
CREATE syntaxe1 CREATE TABLE (colonne1 type1 contrainte1, colonne2 type2 contrainte2 ...)
syntaxe2 CREATE TABLE (colonne1 type1 contrainte1, colonne2 type2 contrainte2 ...) AS Requête
INSERT syntaxe1 INSERT INTO table (col1, col2, ..) VALUES (val1, val2, ...) syntaxe2 INSERT INTO table (col1, col2, ..) (Requête) explication Ces deux syntaxes ont été presentees DELETE syntaxe1 DELETE FROM table WHERE condition explication Cette syntaxe est connue. Ajoutons que la condition peut contenir une Requête avec la syntaxe WHERE expression opérateur (Requête) UPDATE syntaxe1 UPDATE table SET col1=expr1, col2=expr2, ... WHERE condition
WHERE expression opérateur (Requête) syntaxe2 UPDATE table SET (col1, col2, ..)= Requête1, (cola, colb, ..)= Requête2, ... WHERE condition
4.4 Gestion de l'acces concurrent aux données
Appelons environnement de l'utilisateur, les tables et vues auxquelles il peut acceder. Cet environnement est decrit dans la table système ACCESSIBLE_TABLES :
SQL> describe accessible_tables Name Null? Type ---------------------------------------------------------------------------- OWNER NOT NULL CHAR(30) TABLE_NAME NOT NULL CHAR(30) TABLE_TYPE CHAR(11) SQL> select * from accessible_tables where rownum<=10; OWNER TABLE_NAME TABLE_TYPE ----------------- ----------------------------------------------------------- SYS AUDIT_ACTIONS TABLE SYS USER_AUDIT_TRAIL VIEW SYS USER_AUDIT_CONNECT VIEW SYS USER_AUDIT_RESOURCE VIEW SYS DUAL TABLE SYS USER_CATALOG VIEW SYS ALL_CATALOG VIEW SYS ACCESSIBLE_TABLES VIEW SYS USER_CLUSTERS VIEW SYS USER_CLU_COLUMNS VIEW 10 rows selected.
4.4.1 Les privileges d'acces aux tables et vues
syntaxe GRANT privilege1, privilege2, ...| ALL PRIVILEGES ON table/vue TO utilisateur1, utilisateur2, ...| PUBLIC [ WITH GRANT OPTION ]
ALTER droit d'utiliser la commande ALTER TABLE sur la table. DELETE droit d'utiliser la commande DELETE sur la table ou vue. INSERT droit d'utiliser la commande INSERT sur la table ou vue SELECT droit d'utiliser la commande SELECT sur la table ou vue
GRANT update ( col1, col2, ...) ON table/vue TO utilisateur1, utilisateur2, ...| PUBLIC [ WITH GRANT OPTION ] INDEX droit d'utiliser la commande CREATE INDEX sur la table. Trois tables du système donnent des indications sur les privileges accordes ou recus : USER_TAB_GRANTS tables pour lesquelles on a accorde ou recu des privileges USER_TAB_GRANTS_MADE tables pour lesquelles on a accorde des privileges USER_TAB_GRANTS_RECD tables pour lesquelles on a recu des privileges Leur structure est la suivante : SQL> describe user_tab_grants Name Null? Type ---------------------------------------------------------------------- GRANTEE NOT NULL CHAR(30) <-- celui qui recoit le privilege OWNER NOT NULL CHAR(30) <-- le proprietaire de la table ou vue TABLE_NAME NOT NULL CHAR(30) <-- la table ou vue GRANTOR NOT NULL CHAR(30) <-- celui qui accorde les privileges SELECT_PRIV CHAR(1) <-- privilege SELECT (Y : yes ou N : no ) INSERT_PRIV CHAR(1) <-- privilege INSERT DELETE_PRIV CHAR(1) <-- privilege DELETE UPDATE_PRIV CHAR(1) <-- privilege UPDATE REFERENCES_PRIV CHAR(1) ALTER_PRIV CHAR(1) <-- privilege ALTER INDEX_PRIV CHAR(1) <-- privilege INDEX CREATED NOT NULL DATE <-- date d'octroi des privileges SQL> describe user_tab_grants_made Name Null? Type --------------------------------------------------------------------- GRANTEE NOT NULL CHAR(30) TABLE_NAME NOT NULL CHAR(30) GRANTOR NOT NULL CHAR(30) SELECT_PRIV CHAR(1) INSERT_PRIV CHAR(1) DELETE_PRIV CHAR(1) UPDATE_PRIV CHAR(1) REFERENCES_PRIV CHAR(1) ALTER_PRIV CHAR(1) INDEX_PRIV CHAR(1) CREATED NOT NULL DATE SQL> describe user_tab_grants_recd Name Null? Type ---------------------------------------------------------------------- OWNER NOT NULL CHAR(30) TABLE_NAME NOT NULL CHAR(30) GRANTOR NOT NULL CHAR(30) SELECT_PRIV CHAR(1) INSERT_PRIV CHAR(1) DELETE_PRIV CHAR(1) UPDATE_PRIV CHAR(1) REFERENCES_PRIV CHAR(1) ALTER_PRIV CHAR(1) INDEX_PRIV CHAR(1) CREATED NOT NULL DATE SQL> select table_name from tabs; TABLE_NAME ---------------------------------------------------------- ARTICLES BIBLIO BIDON <------------------------------------------------ CLIENTS CMD_ID COMMANDES SAUVEGARDE STOCKS 8 rows selected. SQL> grant select,update on bidon to allo; Grant succeeded. SQL> select grantee,table_name,select_priv,update_priv from user_tab_grants_made; GRANTEE TABLE_NAME S U --------------------------------------------------------------- ALLO BIDON Y A <-- A : ALL (update autorise sur toutes les colonnes)
Remarque:
„« le proprietaire U accordera les droits necessaires grant select to public on T „« l'administrateur donnera un synonyme public a la table T de U create public synonym S for U.T „« tout utilisateur a maintenant acces a la table S select * from S
4.4.2 Suppression des privileges accordes
syntaxe REVOKE privilege1, privilege2, ...| ALL PRIVILEGES ON table/vue FROM utilisateur1, utilisateur2, ...| PUBLIC
Exemple
SQL> revoke all privileges on bidon from allo; Revoke succeeded. SQL> select grantee,table_name,select_priv,update_priv from user_tab_grants_made no rows selected <-- il n'y a plus de privileges sur la table bidon
1 En consultation, un utilisateur travaille sur la table originale. 2 En modification (update, insert, DELETE), les lignes modifiees sont creees en-dehors de la table originale. Celle-ci n'est donc pas modifiee Original -------> ligne modifiee -------> ligne modifiee 3 les lignes de la table originale ne sont accessibles qu'en lecture aux autres utilisateur (ceux qui ont des droits dessus). Toute modification de leur part est bloquee tant que l'utilisateur ayant le premier modifie la table originale n'a pas valide (COMMIT) ou invalide (ROLLBACK) ses modifications, c.a.d. tant qu'il n'a pas termine sa transaction. Quelques commandes generent un COMMIT implicite : a Les commandes qui modifient la structure des tables : CREATE TABLE, ALTER TABLE, DROP TABLE, GRANT b La deconnexion d'Oracle qu'elle soit normale ou anormale (panne système). Dans un contexte multi-utilisateurs, la transaction revet d'autres aspects. Soient deux utilisateurs U1 et U2 travaillant sur la mêmetable TAB : --------+----------+--------+-------+---------------------- T1a T2a T1b T2b La transaction de l'utilisateur U1 commence au temps T1a et finit au temps T1b. La transaction de l'utilisateur U2 commence au temps T2a et finit au temps T2b. U1 travaille sur une photo de TAB prise au temps T1a. Entre T1a et T1b, il modifie TAB. Les autres utilisateurs n'auront acces a ces modifications qu'au temps T1b, lorsque U1 fera un COMMIT.
Cet exemple donne une nouvelle dimension a la transaction : une transaction est une suite coherente de commandes SQL qui doit former un tout indissociable. Prenons un exemple en comptabilite : U1 et U2 travaillent sur des comptes. U1 credite comptex d'une somme et debite comptey de la mêmesomme pendant que U2 consulte les comptes.
Supposons que la transaction de U1 consiste en la mise a jour de comptex suivie de la mise a jour de comptey et que la transaction de U2 consiste en la visualisation de l'etat des comptes. Nous considerons les deux cas possibles :
1 U1 termine sa transaction apres que U2 ne commence la sienne. 2 U1 termine sa transaction avant que U2 ne commence la sienne. Cas 1 Le schema temporel est le suivant : --------+----------+--------+-------+---------------------- T1a T2a T1b T2b
Cas 2 Le schema temporel est le suivant : --------+----------+--------+-------+---------------------- T1a T1b T2a T2b
Supposons maintenant que U1 credite comptex puis valide pour ensuite debiter comptey et valider. Il y alors deux transactions de la part de U1. L'une entre T1a et T1b, l'autre entre T1b et T1c. Supposons que U2 commence sa transaction au temps T2 suivant :
--------+----------+--------+-------+----------------------
T1a T1b T2 T1c
Au temps T2, une photo de la table des comptes est prise pour U2. Sur cette photo, il apparaitra que les comptes ne sont pas equilibres : comptex apparait credite alors que comptey n'apparait pas encore debite. C'est une situation anormale. généralement, ces problemes de transaction seront regles par programme : c'est le concepteur du programme qui choisira les groupes de commandes qui doiventêtre indissociables et donc faire l'objet d'une transaction. Les transactions resteront le plus souvent inconnues des utilisateurs du programme.
4.4.4 Lecture coherente
--------+----------+--------+-------+----------------------
T1a T2a T2b T1b
L'utilisateur U1 fait sa Requête en T1a. Celle-ci est terminee en T1b.
L'utilisateur U2 fait sa modification en T2a. Celle-ci est terminee en T2b.
Entre le temps T1a et le temps T1b, l'etat de la table TAB peut changer : notamment au temps T2b lorsque l'utilisateur U2 valide son travail. Cependant, la Requête de l'utilisateur U1 ne travaille que sur la photo de la table prise au temps T1a. C'est la notion de lecture coherente. Une Requête de consultation travaille sur une photo prise a un instant T ou toutes les données sont dans un etat coherent, stable. Elle ne tient pas compte des changement d'état de la table qui peuvent survenir lors de son exécution.
La lecture coherente s'applique normalement a une commande SQL isolee. On peut l'éténdre a une transaction. Prenons un Exemple :
l'utilisateur U1 fait des statistiques sur la table TAB : 1 select avg(col) from tab;au temps T1 2 select stddev(col) from tab; au temps T2
On peut, pour resoudre le probleme utiliser une transaction speciale appelee une transaction a lecture seulement (Read Only Transaction). Cette transaction prend, lorsqu'elle demarre, une photo de la base et travaille ensuite uniquement sur cette photo, jusqu'a la fin de la transaction. Une telle transaction ne doit comporter que des lectures de la base. Sa syntaxe est la suivante :
SET TRANSACTION READ ONLY; <-- debut de la transaction Commande1; ........................................ Commanden; COMMIT; <-- fin de la transaction
4.4.5 Controle par defaut des acces concurrents
--------+----------+--------+-------+----------------------
T1a T2a T1b T2b
La transaction de l'utilisateur U1 commence au temps T1a et finit au temps T1b.
La transaction de l'utilisateur U2 commence au temps T2a et finit au temps T2b.
Supposons que U1 et U2 travaillent avec un système de reservation de places de train. Au temps T1a, une photo de la table des reservations est prise pour U1 : le siege 12 du wagon 20 du TGV 2040 est libre. L'application le reserve pour U1. Au temps T2a, une photo des reservations est prise pour U2. C'est la mêmeque pour U1 qui n'a pas encore termine sa transaction. L'application risque donc de reserver pour U2 le mêmesiege que pour U1.
Oracle evite ces situations de la facon suivante :
a La commande SELECT
Cette commande ne fait que lire des données. C'est le mecanisme de la photo qui assure que les données recuperees sont des données stables et non en cours d'evolution.
b Commandes de modification du contenu des tables : UPDATE, INSERT et DELETE.
1 Une photo coherente de la table est prise
2 La commande de mise a jour obtient un usage exclusif des lignes a mettre a jour. Elle est la seule a pouvoir les modifier jusqu'a ce que la transaction se termine.
3 Les lectures par d'autres transactions des lignes bloquees sont autorisees. Une photo coherente leur sera fournie.
4 Les autres transactions peuvent faire ce qu'elles veulent sur les lignes non bloquees.
5 Les lignes sont liberees des que la transaction qui les a bloquees est terminee.
c Commandes de modification de la structure d'une table : CREATE, ALTER, DROP :
1 Un COMMIT implicite est genere.
2 La commande obtient un usage exclusif de la table modifiee.
3 Les autres transactions ne peuvent que consulter la table (avec une photo de l'ancienne structure) , elles ne peuvent la modifier.
4 Apres execution de la commande, un COMMIT implicite est genere liberant la table pour les autres transactions.
De nouveau, l'importance de la transaction apparait ici : un utilisateur faisant un UPDATE sur une table bloque les lignes mises a jour jusqu'a la fin de la transaction les rendant indisponibles aux autres utilisateurs qui voudraient les modifier. Il est donc souhaitable d'emettre un COMMIT apres modification des données. Le plus souvent, c'est un programme qui le fera.
Remarque
4.4.6 Controle explicite des acces concurrents
2 Vous voulez travailler avec un etat stable de la base pendant toute la duree d'une transaction. Vous voulez modifier la base. La transaction a lecture seulement ne suffit donc pas : vous demandez un usage exclusif de la table.
Le verrouillage explicite est demande par :
syntaxe LOCK TABLE table1, table2,.. IN mode MODE [NOWAIT] action verrouille table1, table2, ... dans le mode indique par mode : EXCLUSIVE
ROW SHARE
autorise les acces concurrents a la table comme dans la methode par defaut. Empeche de plus un autre utilisateur de poser un verrou exclusif sur la table.
La clause NOWAIT indique qu'il ne faut pas attendre si le verrouillage demande ne peut être obtenu. En son absence, l'utilisateur est mis en attente de la liberation de l'objet demande.
La fin de la transaction (COMMIT/ROLLBACK) enleve tout verrouillage.
4.5 Gestion des performances
les index et les clusters. Nous n'evoquons ici que les index.
4.5.1 Les index
SELECT * FROM biblio WHERE TITRE='Manhattan Transfer'
En faisant de la colonne TITRE, un index, un fichier d'index est cree. Oracle ira alors consulter ce fichier pour rechercher le titre 'Manhattan Transfer'. Ce fichier est organise de maniere a favoriser les recherches. Elle est tres rapide et peu dependante de la taille de la table indexee.
L'indexation ralentit la mise a jour des tables, puisque le fichier index doit suivre ces mises a jour.
La clause UNIQUE demande a ce que deux lignes différentes de table aient deux index différents.
Remarques
Exemples:
SQL> select titre, auteur from biblio; TITRE AUTEUR -------------------- --------------- Les fleurs du mal Baudelaire Tintin au Tibet Herge La terre Zola Madame Bovary Flaubert Manhattan transfer Dos Passos Tintin en Amerique Herge Le pere Goriot Balzac 7 rows selected. SQL> create index titre on biblio(titre); <-- indexation sur les titres des livres Index created. SQL> create index auteur on biblio(auteur); <-- indexation sur la colonne auteur Index created. SQL> create index a date_achat on biblio(achat); <-- indexation sur la date d'achat du livre Index created. SQL> create index genre_prix on biblio (genre,prix) <-- index sur deux colonnes Index created.
4.5.3 Obtenir la liste des index
SQL> describe IND Name Null? Type ----------------------------------------------------------------------- INDEX_NAME NOT NULL CHAR(30) TABLE_OWNER NOT NULL CHAR(30) TABLE_NAME NOT NULL CHAR(30) TABLE_TYPE CHAR(11) UNIQUENESS CHAR(9) TABLESPACE_NAME NOT NULL CHAR(30) INI_TRANS NOT NULL NUMBER MAX_TRANS NOT NULL NUMBER INITIAL_EXTENT NUMBER Conclusion 66 NEXT_EXTENT NUMBER MIN_EXTENTS NOT NULL NUMBER MAX_EXTENTS NOT NULL NUMBER PCT_INCREASE NOT NULL NUMBER SQL> select index_name,table_name,uniqueness from ind; INDEX_NAME TABLE_NAME UNIQUENES --------------------------------------------------------------------- AUTEUR BIBLIO NONUNIQUE DATE_ACHAT BIBLIO NONUNIQUE GENRE_PRIX BIBLIO NONUNIQUE TITRE BIBLIO NONUNIQUE
4.5.4 Abandon d'un index
syntaxe DROP INDEX nom_index action abandonne l'index nomme exemples SQL> drop index genre_prix; <-- abandon d'un index Index dropped. SQL> select index_name from ind; <-- verification INDEX_NAME ------------------------------ <-- il n'est plus la AUTEUR DATE_ACHAT TITRE
4.5.5 Conseils
1 Creer un index sur les colonnes intervenant souvent dans la selection des lignes, c'est a dire dans les clauses WHERE, GROUP BY, ORDER BY
2 Creer un index sur les colonnes qui servent a faire des jointures entre tables.
3 Creer un index pour les grande tables (plusieurs centaines de lignes)
4 Ne pas creer d'index sur des colonnes ayant peu de valeurs differentes ( la colonne genre de la table BIBLIO par exemple).
5 Ne pas creer d'index pour une Requête qui retournera plus du quart des lignes d'une table.
Un index n'est pas toujours utilise. C'est "l'optimiseur" d'Oracle qui decide de l'utiliser ou pas selon des regles qui lui sont propres.
4.6 Le dictionnaire des données
TABS vue - liste des tables creees par l'utilisateur USER_VIEWS table - liste des vues creees par l'utilisateur OBJ vue - liste des objets appartenant a l'utilisateur MYPRIVS vue - privileges de l'utilisateur IND vue - index crees par l'utilisateur USER_TAB_GRANTS_MADE table - privileges accordes par l'utilisateur sur des objets lui appartenant USER_TAB_GRANTS_RECD table - privileges recus par l'utilisateur sur des objets ne lui appartenant pas. COLS vue - liste des colonnes appartenant a l'utilisateur
SQL> describe dict Name Null? Type ------------------------------------------------------------- TABLE_NAME CHAR(30) COMMENTS CHAR(255) SQL> select * from dict; TABLE_NAME COMMENTS ACCESSIBLE_COLUMNS Columns of all tables, views and clusters ACCESSIBLE_TABLES Tables and Views accessible to the user ALL_CATALOG All tables, views, synonyms, sequences accesible to the user ALL_COL_COMMENTS Comments on columns of accessible tables and views ALL_COL_GRANTS Synonym for COLUMN_PRIVILEGES ALL_COL_GRANTS_MADE Grants on columns for which the user is owner or grantor ALL_COL_GRANTS_RECD Grants on columns for which the user or PUBLIC is the grantee ALL_CONSTRAINTS Constraint definitions on accessible tables ALL_CONS_COLUMNS Information about accessible columns in constraint definitions ALL_DB_LINKS Database links accessible to the user ALL_DEF_AUDIT_OPTS Auditing options for newly created objects ALL_INDEXES Descriptions of indexes on tables accessible to the user ALL_IND_COLUMNS COLUMNs comprising INDEXes on accessible TABLES ALL_OBJECTS Objects accessible to the user ALL_SEQUENCES Description of SEQUENCEs accessible to the user ALL_SYNONYMS All synonyms accessible to the user ALL_TABLES Description of tables accessible to the user ALL_TAB_COLUMNS Synonym for ACCESSIBLE_COLUMNS ALL_TAB_COMMENTS Comments on tables and views accessible to the user ALL_TAB_GRANTS Synonym for TABLE_PRIVILEGES ALL_TAB_GRANTS_MADE User's grants and grants on user's objects ALL_TAB_GRANTS_RECD Grants on objects for which the user or PUBLIC is the grantee ALL_USERS Information about all users of the database ALL_VIEWS Text of views accessible to the user AUDIT_ACTIONS Description table for audit trail action type codes. Maps action type numbers to action type names CAT Synonym for USER_CATALOG CLU Synonym for USER_CLUSTERS COLS Synonym for USER_TAB_COLUMNS COLUMN_PRIVILEGES Grants on columns for which the user is the grantor, grantee, or owner, or PUBLIC is the grantee CONSTRAINT_COLUMNS Information about accessible columns in constraint definitions CONSTRAINT_DEFS Constraint Definitions on accessible tables DBA_AUDIT_CONNECT Synonym for USER_AUDIT_CONNECT DBA_AUDIT_RESOURCE Synonym for USER_AUDIT_RESOURCE DBA_AUDIT_TRAIL Synonym for USER_AUDIT_TRAIL DICT Synonym for DICTIONARY DICTIONARY Description of data dictionary tables and views DICT_COLUMNS Description of columns in data dictionary tables and views DUAL IND Synonym for USER_INDEXES MYPRIVS Synonym for USER_USERS OBJ Synonym for USER_OBJECTS SEQ Synonym for USER_SEQUENCES SYN Synonym for USER_SYNONYMS TABLE_PRIVILEGES Grants on objects for which the user is the grantor, grantee, or owner, or PUBLIC is the grantee TABS Synonym for USER_TABLES USER_AUDIT_CONNECT Audit trail entries for user logons/logoffs USER_AUDIT_TRAIL Audit trail entries relevant to the user USER_CATALOG Tables, Views, Synonyms, Sequences accessible to the user USER_CLUSTERS Descriptions of user's own clusters USER_CLU_COLUMNS Mapping of table columns to cluster columns USER_COL_COMMENTS Comments on columns of user's tables and views USER_COL_GRANTS Grants on columns for which the user is the owner, grantor or grantee USER_COL_GRANTS_MADE All grants on columns of objects owned by the user USER_COL_GRANTS_RECD Grants on columns for which the user is the grantee USER_CONSTRAINTS Constraint definitions on accessible tables USER_CONS_COLUMNS Information about accessible columns in constraint definitions USER_CROSS_REFS Cross references for user's views, synonyms, and constraints USER_DB_LINKS Database links owned by the user USER_EXTENTS Extents comprising segments owned by the user USER_FREE_SPACE Free extents in tablespaces accessible to the user USER_INDEXES Description of the user's own indexes USER_IND_COLUMNS COLUMNs comprising user's INDEXes or on user's TABLES USER_OBJECTS Objects owned by the user USER_SEGMENTS Storage allocated for all database segments USER_SEQUENCES Description of the user's own SEQUENCEs USER_SYNONYMS The user's private synonyms USER_TABLES Description of the user's own tables USER_TABLESPACES Description of accessible tablespaces USER_TAB_AUDIT_OPTS Auditing options for user's own tables and views USER_TAB_COLUMNS Columns of user's tables, views and clusters USER_TAB_COMMENTS Comments on the tables and views owned by the user USER_TAB_GRANTS Grants on objects for which the user is the owner, grantor or grantee USER_TAB_GRANTS_MADE All grants on objects owned by the user USER_TAB_GRANTS_RECD Grants on objects for which the user is the grantee USER_TS_QUOTAS Tablespace quotas for the user USER_USERS Information about the current user USER_VIEWS Text of views owned by the user V$ACCESS Synonym for V_$ACCESS V$BGPROCESS Synonym for V_$BGPROCESS V$DBFILE Synonym for V_$DBFILE V$FILESTAT Synonym for V_$FILESTAT V$LATCH Synonym for V_$LATCH V$LATCHHOLDER Synonym for V_$LATCHHOLDER V$LATCHNAME Synonym for V_$LATCHNAME V$LOCK Synonym for V_$LOCK V$LOGFILE Synonym for V_$LOGFILE V$PARAMétéR Synonym for V_$PARAMétéR V$PROCESS Synonym for V_$PROCESS V$RESOURCE Synonym for V_$RESOURCE V$ROLLNAME Synonym for V_$ROLLNAME V$ROLLSTAT Synonym for V_$ROLLSTAT V$ROWCACHE Synonym for V_$ROWCACHE V$SESSION Synonym for V_$SESSION V$SESSTAT Synonym for V_$SESSTAT V$SGA Synonym for V_$SGA V$STATNAME Synonym for V_$STATNAME V$SYSSTAT Synonym for V_$SYSSTAT V$TRANSACTION Synonym for V_$TRANSACTION V$_LOCK Synonym for V_$_LOCK
SELECT col1, col2, ... FROM table.
5 Conclusion
- Détails
- Catégorie : Oracle
- Affichages : 5764
1) Généralités
Avant de commencer à étudier Oracle, rappelons quelques définitions d'ordre général concernant les bases de données.
On appelle LMD (Langage de Manipulation de Données) le langage qui permet l' ajout, la suppression, la modification et l'interrogation des données.
On appelle LCD (Langage de Contrôle de Données) le langage qui permet La gestion des protections d’accès.
• Une requête SQL dans Oracle se termine par un point virgule (;) et
• Un commentaire est encadré par " /*" et "*/" ou précédé par --
2) Organisation du SGBD Oracle
Dès qu'on se connecte à une base de données Oracle, on crée une instance oracle et on peut ainsi accéder à la partie physique du serveur de données Oracle. L'objet de notre article est de présenter les deux parties constitutives de la base de données Oracle,qui sont, instance et partie physique.
Une instance Oracle est un ensemble de processus (Background process et process Server) et une zone mémoire (SGA - Shared Global Area - et PGA - Private Global Area -) qui est caractérisée par son SID appelé ORACLE_SID ; en général, l' OS de la machine sur laquelle est installée la base de données Oracle positionne le SID parmis les variables d'environnement. Une instance ne peut être associée qu'a une et une seule base de données, par contre une base de données peut utiliser plusieurs instances.
Toutes les Instances sont indépendantes les unes des autres. A chacune correspond : Un db_name (nom donné à la base de données dont dépend l'instance) Un SID (identifiant de l'instance) Un ORACLE_SID (variable d'environnement précisant l'instance à joindre) Un Fichier de paramétrage (par défaut initSID.ora) Un fichier de paramétrage serveur (ou SPFILE). Ce fichier est déterminé physiquement par un fichier binaire, mais aussi logiquement, dans l'instance elle-même, par la commande SQL :
Les processus d'arrière plan(Background process) gérent les transferts de données entre la mémoire et le disque dur et traitent un certain nombre d'opérarations nécessaires au bon fonctionnement de la base de données. Les plus importants d'entre eux sont :
Le processus SMON vérifie la synchronisation des données et exécute le contenu des REDO LOG FILE Si l'instance échoue. Il nettoie aussi les segments temporaires après leur utilisation et défragmente les fichiers de données et les tablespaces.
Le processus PMON gère surtout les processus des utilisateurs. Il annule les transactions d'une session (exemple il annule la session d'un utilisatateur si celle-ci échoue) ; il sert aussi à enlever tous les verrous posés lors d'une session, et à relâcher toutes les ressources mises à la disposition pour la session s'il y a eu un échec du système ou de la session utilisateur.
Le processus DBWn est dédié à l'écriture du Database Buffer Cache dans les fichiers de données de la base de données. Ce processus est aussi là pour vérifier en permanence le nombre de blocs libres dans le Database Buffer Cache afin de laisser assez de place disponible pour l'écriture des données dans le buffer.
DBWn se déclenchera lors des événements suivants : - Lorsque le nombre de bloc dirty atteint une certaine limite - Lorsqu'un processus sera à la recherche de blocs libres dans le Database Buffer Cache, et qu'il ne sera pas en mesure d'en trouver. - Lors de timeouts (environ toutes les 3 secondes par défaut) - Lors d'un checkpoint.
Le processus LGWR transcrit les informations contenues dans le REDO LOG Buffer vers les fichiers REDOLOG FILE quand :
- une transaction s'est terminée avec un COMMIT - le REDO LOG Buffer est au 1/3 plein - il y a plus de 1Mo d'informations de log contenues dans le buffer - Avant que DBWn n'écrive le contenu du Database Buffer Cache dans les fichiers du disque dur
Ce processus met à jour les en-têtes des fichiers de données ; il met à jour les fichiers CONTROL FILE pour montrer que l'action de CHECKPOINT s'est bien déroulée, par exemple lors d'un changement de groupe de REDO LOG FILE.
Le CHECKPOINT est un évènement qui se déclenche si on a :
- un changement de groupe de REDO LOG FILE. - un arrêt normal de la base de données (c'est à dire sans l'option ABORT) - une demande explicite de l'administrateur - une limite définie par les paramètres d'initialisation LOG_CHECKPOINT_INTERVAL, LOG_CHECKPOINT_TIMEOUT, et FAST_START_IO_TARGETL'évènement CHECKPOINT va ensuite déclencher l'écriture d'un certain nombre de blocs du Database Buffer Cache dans les fichiers de données par DBWn après que LGWR ait fini de vider le REDO LOG Buffer. Le nombre de blocs écrits par DBWn est défini avec le paramètre FAST_START_IO_TARGET si celui-ci a été défini.
Le processus ARCn a comme seule fonction de copier un fichier REDO LOG FILE à un autre emplacement. Cette copie se déclenchera automatiquement en mode ARCHIVELOG lors du changement de groupe de REDO LOG FILE. Quand on est en mode NOARCHIVELOG le processus n'existe pas.
Les processus serveurs (process server) gérent les requêtes des utilisateurs provenant des connections à la base de données; ils sont chargés de la communication entre la SGA et le processus utilisateur. Ils permettent ainsi d'analyser, d'exécuter les requêtes SQL des utilisateurs, de lire les fichiers de données, de placer les blocs de données correspondants dans la SGA et de Renvoyer les résultats des commandes SQL au process utilisateur.
On a bien dit qu' une instance Oracle est composé de processus et de deux grandes zones mémoire principales appelées SGA et PGA; étudions les en détail.
Pour fonctionner, Oracle a besoin de beaucoup de mémoire ; il utilise une partie de cette mémoire appelée SGA pour mettre en place le macanisme de partage d'informations entre ses différents processus ; SGA est composée de quatre grandes parties et chacune d'elles joue un rôle très important :
La zone mémoire Shared Pool appelée aussi "zone de mémoire partagée", sert à Oracle pour le partage des informations sur les objets de la base de données et sur les droits et privilèges accordés aux utilisateurs. Elle est répartie en deux parties à savoir La Library Cache et Le Dictionnary Cache.
La Library Cache stocke les informations sur les ordres SQL récemment exécutés dans une zone SQL Cache qui contiendra le texte de l'ordre SQL, la version compilée de l'ordre et son plan d'exécution. Lorsqu'une requête est exécutée plusieurs fois, Cette zone mémoire sera utilisée pour garder les informations et ainsi Oracle n'aura pas à recréer la version compilée de la requête et le plan d'exécution de la requête.
Le Dictionnary Cache, quant à elle, contient les définitions (i.e la structure, les composants, les privilèges liés à cet objet) des objets de la base de données utilisés récemment.
Ains, à chaque exécution d'une requête, Oracle n'aura pas à aller chercher ces informations sur le disque : il les a en mémoire dans la dictionnary cache.
La deuxième partie de la SGA est la Data Buffer Cache
Dans cette zone de mémoire on garde les blocs de données qui ont été récemment utilisées ; cette technique permet à Oracle de recupérer la première fois les données à partir du disque dur et, s'il a encore besoin des mêmes données, il les récupère dans la Data Buffer Cache; cela permet un gain de temps non négligeable.
Comme les autres zones définies ci-dessus, Database Buffer Cache a son paramètrage défini dans le fichier de configuration int.ora
Cette zone mémoire est définie par 2 paramètres du fichier init.ora
DB_BLOCK_SIZE : Ce paramètre, défini lors de la création de la base de données, représente la taille d'un bloc de données Oracle. Celui-ci est défini de manière définitive et ne pourra plus être modifié.
DB_BLOCK_BUFFERS : Ce paramètre défini le nombre de blocs Oracle qui pourront être contenus dans le Database Buffer Cache. Ainsi pour obtenir la taille du Database Buffer Cache on effectuera l'opération
Cette zone mémoire de type circulaire,et dont on pourra changer la taille avec le paramètre LOG_BUFFER (en Bytes), sert exclusivement à enregistrer toutes les modifications apportées sur les données de la base. Le fait que cette zone mémoire soit de type circulaire et séquentielle, signifie que les informations des toutes les transactions sont enregistrées en même temps. Le fait que ce buffer soit circulaire signifie que Oracle ne pourra écraser les données contenues dans ce buffer que si elles ont été écrites dans les fichiers REDOLOG FILE.
Contrairement aux autres zones mémoire, celle-ci n'est pas partagée. Elle est seulement utilisée par des processus serveur ou processus d'arrière plan. Elle est allouée lors du démarrage du processus et désallouée lors de l'arrêt du processus.
Elle contient :
- La zone de tri : Appelée SORT AREA, c'est dans cette zone que seront effectués les tris pour les requêtes lancées par l'utilisateur.
- Les informations de sessions : Cette zone contiendra les informations de sessions, les privilèges de l'utilisateur, ainsi que des statistiques de tuning concernant la session.
- L'état des curseurs : Cette zone permettra de connaître l'état des curseurs de l'utilisateur.
- Le Stack Space : Cette zone contiendra toutes les autres variables d'environnement et de session de la session de l'utilisateur.
On peut modifier la taille de la SORT AREA en changeant la valeur du paramètre SORT_AREA_SIZE.
La partie physique du serveur de données oracle est un ensemble de fichiers :
Les fichiers d'extension ".dbf" sont des fichiers de données; ils contiennent les tables, les index, les procédures, les fonctions, etc.., sans oublier le dictionnaire (créé lors de la création d'une base de données).
Les données dont on parle ici ne sont pas toutes des données au sens de données créées ou manipulables par le BDA ou le developpeur.
Les tables, les index, les vues, les synonymes, les databases links, les procédures stockées ne sont pas des données au sens où on le définit dans la base de données. L'écriture dans ces fichiers (au format propriétaire Oracle) est assurée par le processus LGWR (Log Writer) dont nous verons les détails plus tard.
Ces fichiers de journalisation, d'extension ".rdo" ou ou ".log", contiennent l'historique des modifications apportées à la base de données Oracle. Ils enregistrent les modifications successives de la base de données et permettent ainsi sa restauration en cas de défaillance d'un disque dur.
les fichiers Redo-log doivent être archivés avec une fréquence raisonnable (toutes les 3 ou 2 heures) et si c'est possible, sur des disques autres que ceux sur lesquels tourne la base de données Oracle, et pour des raisons de sécutité évidente, on doit avoir au moins deux fichiers Redo-log.
Ces fichiers doivent avoir une taille raisonnable qui permet une reconstruction rapide de la base en cas de crash car, s'ils sont gros, leur archivage est moins rapide.
Remarque :
Le cas échéant, la base de données Oracle est à même de simuler l'ensemble des commandes n'ayant pas été sauvegardées pour rétablir le contenu de la base de données.
Oracle propose également un mode d' archivage permettant la sauvegarde du fichier Redo-log avant sa réutilisation pour restaurer la base. Toutefois, Si ce mode n'a pas été activé, le contenu du fichier Redo Log est supprimé après utilisation. Enfin ces fichiers peuvent être dupliqués dans des répertoires de groupe afin de fournir un maximum de sécurité.
Ces fichiers sont créés lors de la création de la base de données et servent à stocker son état. Lors de l'initialisation de la base, ils permettent de savoir si celle-ci a été arrêtée correctement, mais aussi de savoir l'emplacement des fichiers de données et des fichiers Redo Log. Les fichiers de contrôle sont eux-mêmes repérés par le fichier d'initialisation. Le fichier de contrôle contient les informations suivantes :
- Nom de la base de données - Date et heure de création de la base - L'emplacement des fichiers journaux (Redo-Log) - Les informations de synchronisation.le paramètre db_create_online_log_dest_n (si il est configuré) indique où créer les fichiers de contrôle. Si db_create_file_dest se trouve dans le fichier de paramètres, c'est lui qui indiquera à Oracle où créer l'unique fichier de contrôle.
3) Tablespace
Un tablespace est une partition logique contenant un ou plusieurs fichiers. Une base peut être décomposée en plusieurs tablespaces.
Un fichier appartient à un et un seul tablespace. Un tablespace peut s'étendre soit, par ajout (on-line) d'un fichier, soit par auto-extension du fichier du tablespace ; l'ajout ou l'extension automatique se font de la façon suivant :
L'ajout d'un fichier au tablespace se fait par chaînage au premier en procédant de la façon suivante
Un tablespace contient au moins un fichier. Celui-ci est créé automatiquement lors de la création du tablespace par Oracle, en fonction des paramètres donnés par la commande.
Par défaut il existe toujours un tablespace baptisé SYSTEM qui contient le dictionnaire de données et le rollback segment SYSTEM (dans le cas ou il n'existe pas d'UNDO tablespace). On peut également stocker les datas et les index dans ce même tablespace, et on obtient ainsi une base minimale, peu structurée, peu performante et peu sécurisée .
C'est un peu l'équivalent de la table mysql pour la base de données MySQL.
Un tablespace temporaire est un tablespace spécifique aux opérations de tri pour lesquelles la SORT_AREA_SIZE ne serait pas suffisamment grande. Il n'est pas destiné à accueillir des objets de la base de données et son usage est réservé au système. Depuis la version Oracle 9i, on peut définir un tablespace par défaut au niveau base de données(à la création de la base) ou utilisateur ; chaque utilisateur peut avoir son propre tablespace temporaire ce qui est particulièrement pratique s'il existe un utilisateur spécifique pour les gros batchs par exemple.
Le tablespace UNDO, comme son nom l'indique, est réservé exclusivement à l'annulation des commandes DML (UPDATE, INSERT, etc...).
Lorsqu'on exécute l'ordre DELETE par exemple, Oracle commence par copier les lignes à supprimer dans le tablespace UNDO et ensuite indique que les blocs contenant les données dans le tablespace d'origine sont libres.
Un ROLLBACK permet de revenir en arrière alors que le COMMIT supprimera les lignes du tablespace UNDO (on comprend mieux ici pourquoi un DELETE est si long - 2 écritures pour une suppression-). Le tablespace UNDO est unique pour une base de données .
Le tablespace transportable, introduit dans la version 8i, sert à copier les données entre deux bases de données. Depuis la 9i, la taille des blocs de la base ne doit plus être nécessairement identique.
Pour qu'un tablespace puisse être transporté, il doit contenir tous les objets interdépendants. On ne pourra pas par exemple transporter un tablespace qui contient une table dont les index seraient créés dans un autre tablespace.
4) Les segments
Un segment est un objet occupant de l’espace dans la base de données. Il est constitué d’un ou plusieurs extents. c'est à dire d’un ensemble de blocs contigus permettant de stocker un certain type d’information. Des extents sont ajoutés lorsqu’un segment nécessite davantage d’espace.
Les différents types de segments sont les suivants : - Table - Partition de table - Cluster - Table organisée en index - Segment LOB - Table imbriquée - Index - Partition d'index - Index lob - Rollback segment - Segment temporaire - Segment de démarrage
.........
5) Définitions des tables
syntaxe:
CREATE TABLE nom_table (Attribut1 TYPE, Attribut2 TYPE, ..., contrainte_integrité1, contrainte_integrité2,...);
• NUMBER(n) : Entier à n chiffres
• NUMBER(n, m) : Réel à n chiffres au total
(virgule comprise), m après la virgule
• VARCHAR(n) : Chaîne de n caractères (entre ‘ ’)
• DATE : Date au format ‘JJ-MM-AAAA’
Détaillons les différents éléments ci-dessus:
la requête sql CREAT TABLE est suivie du nom de la table que l'on veut créer; ensuite, viennent entre parenthèses les différents attributs, chacun avec son TYPE.
Ensuite viennent les contraintes(s'il y en a); on verra un peu plus loin comment elles sont définies.
Un nom de table doit être unique et ne doit pas être un mot clé SQL. Une table doit contenir au minimum une colonne et au maximum 254 colonnes.
La définition élémentaire d'une colonne consiste à lui attribuer un nom et un type.
Imaginons une entreprise qui veut mettre dans une base de données les informations concernant ses employés ; on commence par créer une table qu' on peut appeler par exemple Employes ; cette table Employee représente les employés et voici son shéma :
Employes(NumCli,Nom, DateNaissance, Salaire, NumEmp).
La création, comme on l'a dit un peut plus haut, se fait de la façon suivante:
CREATE TABLE Employes ( NumCli NUMBER(3), Nom CHAR(30), DateNaiss DATE, Salaire NUMBER(8,2), NumEmp NUMBER(3), CONSTRAINT cle_pri PRIMARY KEY (NumCli), CONSTRAINT cle_etr FOREIGN KEY (NumEmp) REFERENCES EMPLOYEUR(NumEmp), CONSTRAINT date_ok CHECK (DateNaiss < SYSDATE));
Les contraintes d'intégrité
- caractère obligatoire ou facultatif, - unicité des lignes, - clé primaire, - intégrité référentielle, - contrainte de valeurs.Les contraintes peuvent s'exprimer soit au niveau colonne (local) soit au niveau table (contraintes globales).
A chaque expression de contrainte est affectée un nom de contrainte, soit de façon implicite par le SGBD, soit de façon explicite par la clause CONSTRAINT
CREATE TABLE articles ( Numero NUMBER(6) CONSTRAINT pk_artiles PRIMARY KEY, designation VARCHAR(255) UNIQUE, prix NUMBER(8,2) NOT NULL, couleur VARCHAR(32) );
- contraintes sur les colonnes
- contraintes sur les tables
Il est possible de spécifier des contraintes d'intégrité au niveau des colonnes lors de la phase de création de la table. Si la table est déja créée, il est possible d'utiliser l'instruction ALTER TABLE. Une contrainte d'intégrité est spécifiée juste après le type de la colonne, et il est possible d'en définir plusieurs. La syntaxe générale est:
[CONTRAINT contrainte]
{[NOT] NULL
/{UNIQUE/PRIMARY KEY}
/REFERENCES nom_table[(colonne)]
[ON DELETE CASCADE]
/CHECK (condition) }
{[DISABLE]}
Par défaut Oracle attribut comme nom de contrainte SYS_Cn, où n est un entier.
Exemple:
Si on désire imposer d'avoir toujours une valeur dans l'attribut pnom de la table pièce P ci-dessus, on peut écrire lors de la définition de cette colonne:
CREATE TABLE P (..., pnom varchar(20) CONSTRAINT C_pnom NOT NULL,...)
Jusqu'à présent nous avons présenté les contraintes spécifiées au niveau d'une colonne, cependant on peut avoir besoin de spécifier une contraine relative à deux ou plusieurs colonnes. C'est le cas quand on a une clé primaire composée de deux colonnes ; on parle alors de contrainte d'intégrité de table. La syntaxe générale est:
[CONTRAINT contrainte]
{[NOT] NULL
/{ {UNIQUE/PRIMARY KEY}(colonne, [,colonne]...)
/FOREIGN KEY (colonne, [,colonne]...)
REFERENCE Snom_table[(colonne [,colonne]...)]
[ON DELETE CASCADE]
/CHECK (condition) }
{[DISABLE]}
...... à suivre
...... à suivre
6) Les vues
Dans les SGBD relationnels, la notion de schéma externe correspond au concept de table dérivée. On distingue deux types de tables dérivées : les vues et les instantannés. Une vue ou table virtuelle n'a pas d'existence propre : sa consommation en ressources consiste seulement en sa description dans le dictionnaire de données.
On parle de "vue" car il s'agit simplement d'une représentation des données dans le but d'une exploitation visuelle. Les données présentes dans une vue sont définies grâce à une clause SELECT
CREATE VIEW Vue (colonneA,colonneB,colonneC,colonneD) AS SELECT colonne1,colonne2,colonneI,colonneII FROM Nom_table1 Alias1,Nom_tableII AliasII WHERE Alias1.colonne1 = AliasII.colonneI AND Alias1.colonne2 = AliasII.colonneII
La spécification des noms des colonnes de la vue est facultative. Par défaut, les colonnes de la vue ont pour nom les noms des colonnes résultat de la requête.
La clause WITH CHECK OPTION empêche que l'utilisateur ajoute ou modifie dans une vue des lignes non conformes à la définition de la vue.
Mais, pour faire une mise à jour au travers d'une vue, il doit être possible de propager la mise à jour sur les tables source. La mise à jour d'une vue ne peut se faire donc que si :
- La clause FROM ne fait référence qu'à une seule table ou à une vue accessible en mise à jour,
- Elle ne comporte pas de DISTINCT ou de fonction sur colonne (SUM, COUNT : : : ), De manière simplifiée, on peut dire que les ordres INSERT, DELETE et UPDATE ne peuvent s'appliquer qu'à une vue n'utilisant qu'une seule table avec restrictions et projections.
Une vue peut être détruite par la commande :
<instruction drop vue> : := DROP VIEW <nom de la vue>
SELECT * FROM USER_VIEWS
7) snapshot (Un cliché instantanné)
a) le résultat est conservé dans la base de données comme une seule relation accessible en lecture seulement ;
b) périodiquement, l'instantanné est rafraîchi c'est à dire, sa valeur courante est écartée, la requête est exécutée à nouveau et le résultat devient la nouvelle valeur de l'instantanné. Cette technique permet de créer sur une base distante un cliché d'une table complète ou partielle ou même un cliché du résultat d'une requête complexe effectuée sur la base maître.
La création se fait par :
<instruction create snapshot> : := CREATE SNAPSHOT <nom du cliché> REFRESH [FAST j COMPLETE j FORCE] [START WITH date] [NEXT date] AS < expression requête >
FAST définit un mode de rafraîchissement rapide qui met à jour uniquement les lignes modifiées de la base maître.
COMPLETE définit un mode rafraîchissement complet qui ré-exécute la requête du cliché
FORCE (par défaut) effectue un rafraîchissement rapide si possible, sinon effectue un rafraî- chissement complet
START WITH définit la date du premier rafraîchissement
NEXT définit l'intervalle entre deux rafraîchissements.
8) Index
Si on crée un index sur une colonne d'une base de données, il faut toujours avoir à l'esprit qu'il utilise de l'espace mémoire, et, étant donné qu'il est mis à jour à chaque modification de la table à laquelle il est rattaché, il peut alourdir le temps de traitement du SGBDR lors de la saisie de données.
La création d'index doit être justifiée et les colonnes sur lesquelles il porte doivent être judicieusement choisies pour minimiser les doublons et le temps d'accès.
Les index sont des structures permettant de retrouver une ligne dans une table à partir de la valeur d'une colonne ou d'un ensemble de colonnes. Un index contient la liste triée des valeurs des colonnes indexées avec les adresses des lignes (numéro de bloc dans la partition et numéro de ligne dans le bloc) correspondantes.
Tous les index oracle sont stockés sous forme d'arbres équilibrés (btree) ; cette une structure arborescente permet de retrouver rapidement dans l'index la valeur de clé cherchée, et donc l'adresse de la ligne correspondante dans la table.
Dans un tel arbre, toutes les feuilles sont à la même profondeur, et donc la recherche prend approximativement le même temps quelle que soit la valeur de la clé.
Lorsqu'un bloc d'index est plein, il est éclaté en deux blocs ; en conséquence, tous les blocs d'index ont un taux de remplissage variant de 50% à 100%.
Remarque :
Sans index on balaie séquentiellement toute la table quelle que soit la position de l'élément recherché.
L'adjonction d'un index à une table ralentit les mises à jour (insertion, suppression, modification de la clé) mais accélère beaucoup la recherche d'une ligne dans la table.
L'index accélère la recherche d'une ligne à partir d'une valeur donnée de clé, mais aussi la recherche des lignes ayant une valeur d'index supérieure ou inférieure à une valeur donnée, car les valeurs de clés sont triées dans l'index.
La création d'index en SQL se fait grâce à la clause INDEX précédée de la clause CREATE. Elle permet de définir un index désigné par son nom, portant sur certains champs d'une table. La syntaxe est la suivante:
CREATE [UNIQUE] INDEX Nom_de_l_index ON Nom_de_la_table (Nom_de_champ [ASC/DESC], ...)
9) Exemples
On va proposer des entités-associations qui modélisent le cas ci-dessous tout en précisant en français les contraintes .
La bibliothèque d'une petite ville possède deux points de prêt. Ces 2 centres disposent d'ordinateurs personnels interconnectés qui permettent de gérer les emprunts.
En dialoguant avec les bibliothécaires on a déterminé les faits suivants:
- un client qui s'inscrit à la bibliothèque verse une caution. Suivant le montant de cette caution il aura le droit d'effectuer en même temps de 1 à 10 emprunts;
- les emprunts durent au maximum 8 jours;
- un livre est caractérisé par son numéro dans la bibliothèque (identifiant), son éditeur et son (ses) auteur(s);
- on veut pouvoir obtenir, pour chaque client les emprunts qu'il a effectué (nombre, numéro et titre du livre, date de l'emprunt) au cours des trois derniers mois;
- toutes les semaines, on édite la liste des emprunteurs en retard :
nom et adresse du client, date de l'emprunt, numéro(s) et titre du (des) livre(s) concerné(s);
- on veut enfin pouvoir connaître pour chaque livre sa date d'achat et son état.
Notre démarche consiste à élaborez un diagramme entité-association pour la base de données de la bibliothèque en précisant les contraintes d'intégrité.
exemple de contrainte : pour chaque livre la date d'achat doit être antérieure aux dates d'emprunt.
Un éditeur souhaite installer une base de données pour mémoriser les informations suivantes :
- les livres sont identifiés par leur n° ISBN. Un livre possède un titre et un prix de vente. - Il est écrit par un ou plusieurs auteurs.
- Chaque livre est tiré en une ou plusieurs éditions, datées et identifiées par leur ordre (première édition, seconde édition, etc.). - Chaque édition comporte un certain nombre d'exemplaires. Un livre peut être primé (Goncourt, Fémina etc.).
- les auteurs sont identifiés par leur nom et prénom et peuvent avoir un pseudonyme. - Pour chaque livre, un auteur perçoit des droits d'auteur, calculés comme un pourcentage du prix de vente (il est aussi fonction du nombre d'auteurs, du tirage, etc.).
- les libraires (identifiés par leur nom et adresse complète) peuvent envoyer des commandes d'un ou plusieurs livres en quantité quelconque.
Sous-requêtes
WHERE expression opérateur_de_comparaison {ALL/ANY/SOME} (requête SELECT)
WHERE expression [NOT] IN (requête SELECT)
WHERE [NOT] EXISTS (requête SELECT)
- Les sous-requêtes situées après les mots-clé IN, ALL, ANY et SOME doivent avoir le même nombre de colonnes que celui spécifié dans l'expression.
- Ces sous-requêtes peuvent rendre plusieurs valeurs qui seront évaluées en fonction de l'opérateur de comparaison: ALL/ANY/SOME:
la condition est vraie si la comparaison est vraie pour chacune des valeurs retournées par la sous-requête.
- Détails
- Catégorie : Oracle
- Affichages : 6248
ANNEXES
A.1) Créer une base
Choisissons" Créer une table en mode Création" et définissons une première table de la façon qui suit : Fermer la fenêtre de définition de la table et donnez a celle-ci le nom T1 :
La table créée apparaît dans la structure de la base test :
La structure de la table t1 peut être modifiée. Cliquez droit sur t1 et choisissez Mode création :
Faisons du champ id de t1 une clé primaire. Pour cela, sélectionnez le champ id et l'option de menu Édition/Clé primaire. Une clé apparaît alors a gauche du champ id.
Fermez la fenêtre et sauvegardez. On revient a la structure de la base :
Cliquez droit sur t1 et choisissez l'option Ouvrir :
Créez maintenant quelques lignes dans la table t1 :
Fermez la fenêtre et sauvegardez. De la même façon que précédemment, créez une autre table t2 qui aurait la structure suivante :
Le champ idT2 est la clé primaire de la table. Le champ idT1 est une clé étrangère référençant le champ id de la table t1. Le contenu de t2 pourrait être le suivant :
Nous avons maintenant deux tables dans notre base test.
A.2) Générer des Requêtes SQL
On peut aussi utiliser des Requêtes SQL de définition de données:
On peut alors vérifier la présence de la table t1 dans la structure de la base:
et vérifier sa structure:
On a donc la un outil convivial pour apprendre SQL. On peut également utiliser Microsoft Query, un outil livre avec MS Office.